









Blaze 是快手自研的基于Rust语言和DataFusion框架开发的Spark向量化执行引擎,旨在通过本机矢量化执行技术来加速Spark SQL的查询处理。现已开源发布,开源版本全面兼容Spark 3.0~3.5。
公告称,在TPC-DS 1TB的测试中,Blaze相较于Spark 3.3版本减少了60%的计算时间、Spark 3.5版本减少了40%的计算时间,并大幅降低了集群资源的消耗;此外,Blaze在快手内部上线的数仓生产作业也观测到了平均30%的算力提升,实现了较大幅度的降本增效。
Spark+Blaze 的架构设计原理如下图:
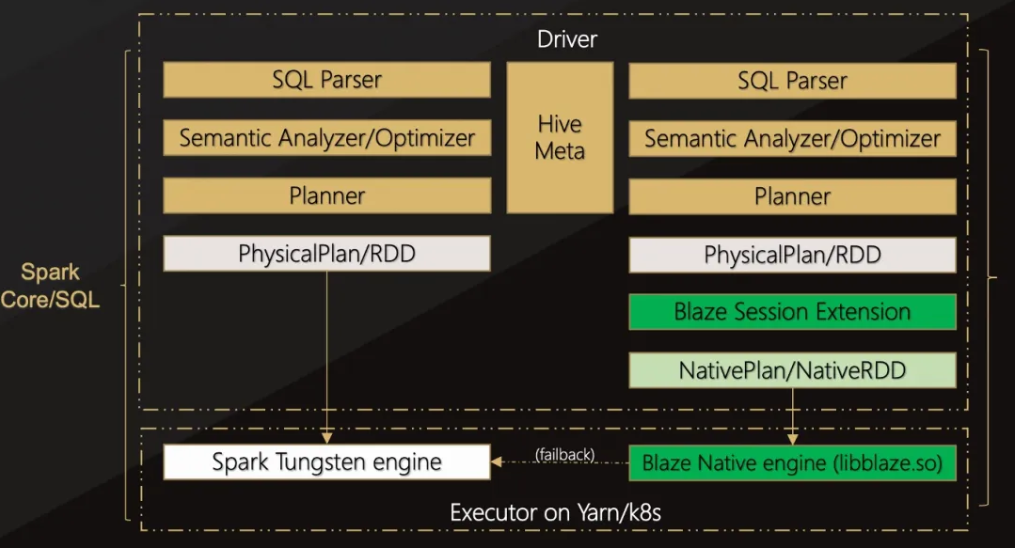

Blaze 架构中的核心模块有四个,共同驱动着大数据性能的显著提升。这些模块分别为:
- Native Engine:基于 Datafusion 框架实现的与 Spark 功能一致的 Native 算子,以及相关内存管理、FFI 交互等功能。
- ProtoBuf:定义用于 JVM 和 native 之间的算子描述协议,对 Datafusion 执行计划进行序列化和反序列化。
- JNI Bridge:实现 Spark Extension 和 Native Engine 之间的互相调用。
- Spark Extension:Spark 插件,实现 Spark 算子到 Native 算子之间的翻译。
具体而言,Blaze 目前已具备以下关键能力:
- Parquet向量化读写能力:实现了对Parquet格式数据的高效向量化读写,极大地提升了数据处理的速度与效率。
- 全面算子与表达式支持:覆盖了线上常用的所有算子与表达式,少量不支持的表达式和UDF也可以细粒度回退,确保用户能够无缝迁移并享受向量化处理带来的性能提升。
- Remote Shuffle Service集成:内部集成了自研的Remote Shuffle Service,同时我们也在和阿里合作,增加对Apache Celeborn 的支持,预计9月份可以提交到社区。
- TPC-H/TPC-DS测试优异表现:在业界权威的TPC-H/TPC-DS基准测试中,Blaze成功通过全部测试场景,并以TPC-H平均3倍以上、TPC-DS 2.5倍的性能提升展示了其在复杂查询处理上的卓越能力。
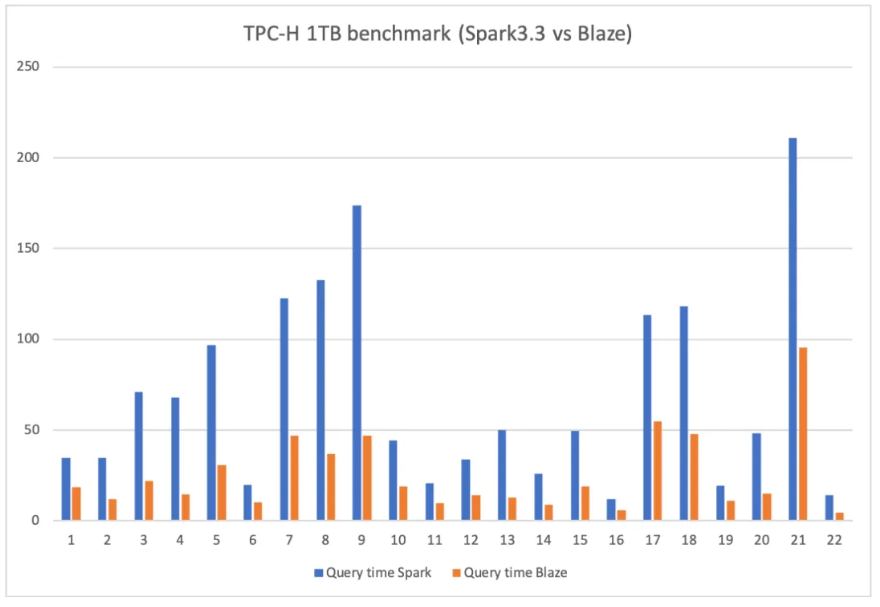
在真实的生产环境中,向量化引擎大规模上线应用,算力平均提升 30%+,成本节约年化数千万元。
未来规划
- 持续迭代优化,内部线上推全。
- 支持更多引擎或场景,例如数据湖等。
- 加强开源社区运营建设,共建生态繁荣。
更多详情可查看官方公告。




















































