









由集中式系统到分布式系统的发展,事务的原则也有原先的ACID发展成了CAP/BASE。
ACID
事务(Transaction)是由一系列对系统中数据进行访问和更新的操作锁组成的一个程序执行逻辑单元(Unit),狭义上的事务特指数据库事务。
事务具有四个特征,分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),简称事务的ACID特性。
原子性:事务必须是一个原子的操作序列单元,要么全部成功,要么全部失败。
一致性:事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。
隔离性:并发的事务是相互隔离的,一个事务的执行不能被其他事务干扰,定义了4个事务隔离级别。
持久性:事务一旦提交,他对数据库中对应数据的状态变更就应该是永久性的。
CAP和BASE理论
集中式系统中事务可以容易的满足ACID这几个特性,但是对于一个高访问量、高并发的互联网分布式系统来说,如果我们期望实现一套严格满足ACID特性的分布式事务,很可能出现的情况就是在系统的可用性和严格一致性之间出现冲突,因为当我们要求分布式系统具有严格一致性时,很可能就需要牺牲掉系统的可用性。可用性和一致性又是分布式系统不可或缺的两个属性,在可用性和一致性之间永远无法存在一个两全其美的方案,于是出现了诸如CAP和BASE这样的分布式系统经典理论。
CAP定理
一个分布式系统不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三个基本需求,最多只能同时满足其中的两项。
一致性:所有节点在同一时间具有相同的数据,注:这里的一致性和ACID中的一致性是不一样的
可用性:服务一直可用,而且是正常响应时间
分区容错性:分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
CAP证明
关于CAP定理中为什么只能同时满足其中的两项,这里可以做一个简单的证明:
前提:对于一个分布式系统而言,分区容错性可以说是一个最基本的要求。因为既然是一个分布式系统,那么分布式系统中的组件必然需要被部署到不同的节点,否则也就无所谓分布式系统了
假设网络中有2个节点N1和N2,N1和N2上分别安装了数据库D1(主)和D2(备)形成主备模式,D1(主)负责写并且读,D2(备)分担一部分读
正常情况下:D1(主)写完数据,同步到D2(备),读取D2可以读到最新的数据
非正常情况下:作为一个分布式系统,它和单机系统的最大区别,就在于网络,现在假设一种极端情况,N1和N2之间的网络断开了;D1(主)写完数据,D2(备)没有更新到最新的数据;这时候怎么办,有2个选择:第一,牺牲数据一致性,响应旧的数据给用户;第二,牺牲可用性,阻塞等待,直到网络连接恢复,数据更新操作完成之后,再给用户响应最新的数据。
BASE理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的简写。很明显BASE理论更加倾向满足CAP理论中的AP,既满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
CAP、ACID以及BASE之间的关系
网上看到过一张图片,感觉对三者之间的关系描述的很清晰,如下图所示:
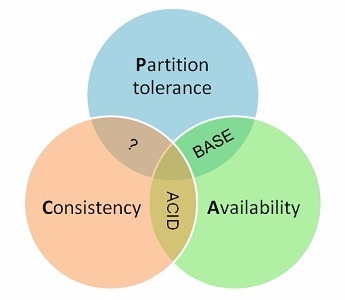
CAP理论中根据倾向的不同:
CA – 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大(ACID)
AP – 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些(BASE)
CP – 满足一致性,分区容忍必的系统,通常性能不是特别高(BASE)个人认为里面的?也可以写成BASE
其实我们还可以从数据库这个角度来看:
关系型数据库和非关系型数据库也能在CAP理论中得到体现,如下图所示(来源网上):
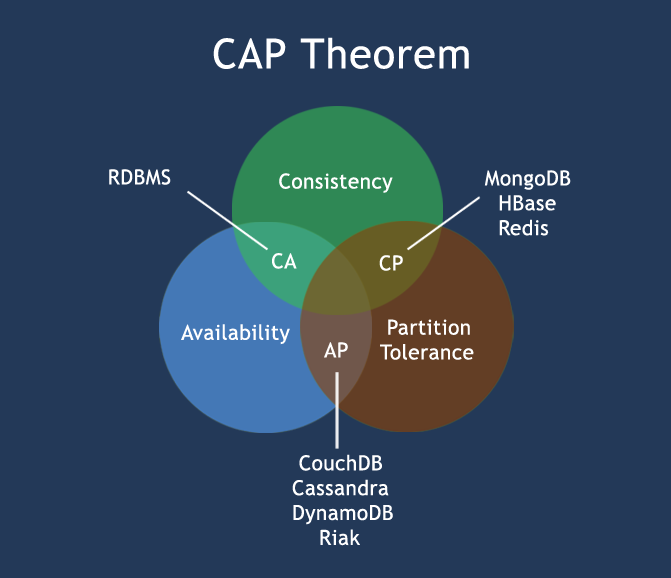
关系型数据库(RDBMS)遵循ACID原则,非关系型数据库遵循BASE原则
总结
ACID强一致性模型,而BASE提出通过牺牲强一致性来获得可用性但最终达到一致状态;在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计中,ACID特性和BASE理论往往会结合在一起使用。






















































