









单机
redis最主要的适用场景:少量数据存储,高速读写访问,数据全部in-momery 的方式来保证高速访问,同时提供数据落地的功能。
分布式
随着用户量的增长,数据量随之增长,大型网站应用,热点数据量往往巨大,几十G上百G是很正常的事儿,这时候我们需要横向扩展,多台主机共同提供服务,既分布多个redis协同工作。大致有如下几种集群方案:
方案一:Redis官方集群方案Redis Cluster
Redis Cluster由3.0版本正式推出,是一种服务器sharding技术,对客户端来说是完全透明的。
Redis Cluster中,Sharding采用slot(槽)的概念,一共分成16384个槽。对于每个进入Redis的键值对,根据key进行散列,分配到这16384个slot中的某一个中。使用的hash算法也比较简单,就是CRC16后16384取模。
Redis集群中的每个node(节点)负责分摊这16384个slot中的一部分,也就是说,每个slot都对应一个node负责处理。当动态添加或减少node节点时,需要将16384个槽做个再分配,槽中的键值也要迁移。当然,这一过程,在目前实现中,还处于半自动状态,需要人工介入。
Redis集群,要保证16384个槽对应的node都正常工作,如果某个node发生故障,那它负责的slots也就失效,整个集群将不能工作。
为了增加集群的可访问性,官方推荐的方案是将node配置成主从结构,即一个master主节点,挂n个slave从节点。这时,如果主节点失效,Redis Cluster会根据选举算法从slave节点中选择一个上升为主节点,整个集群继续对外提供服务。这非常类似前篇文章提到的Redis Sharding场景下服务器节点通过Sentinel监控架构成主从结构,只是Redis Cluster本身提供了故障转移容错的能力。
Redis Cluster的新节点识别能力、故障判断及故障转移能力是通过集群中的每个node都在和其它nodes进行通信,这被称为集群总线(cluster bus)。它们使用特殊的端口号,即对外服务端口号加10000。例如如果某个node的端口号是6379,那么它与其它nodes通信的端口号是16379。nodes之间的通信采用特殊的二进制协议。
对客户端来说,整个cluster被看做是一个整体,客户端可以连接任意一个node进行操作,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node,这有点儿像浏览器页面的302 redirect跳转。
Redis Cluster是Redis 3.0以后才正式推出,时间较晚,目前能证明在大规模生产环境下成功的案例还不是很多,需要时间检验。
方案二:Redis Sharding集群
这种方案把sharding完全放在客户端,每个redis都是独立的存在,其只要思想是将key进行散列,通过hash函数,不同的key映射到指定的redis节点上。
jedis已经很好的支持了redis sharding功能:
JedisShardInfo jedisShardInfo1 = new JedisShardInfo(bundle.getString("redis1.ip"),
Integer.valueOf(bundle.getString("redis.port")));
JedisShardInfo jedisShardInfo2 = new JedisShardInfo(bundle.getString("redis2.ip"),
Integer.valueOf(bundle.getString("redis.port")));
List list = new LinkedList();
list.add(jedisShardInfo1);
list.add(jedisShardInfo2);
ShardedJedisPool pool = new ShardedJedisPool(config, list);
ShardedJedis jedis = pool.getResource();此模式下的扩容问题,作者给出了解决方案
Redis的作者提出了一种叫做presharding的方案来解决动态扩容和数据分区的问题,实际就是在同一台机器上部署多个Redis实例的方式,当容量不够时将多个实例拆分到不同的机器上,这样实际就达到了扩容的效果。
拆分过程如下:
1.在新机器上启动好对应端口的Redis实例。
2.配置新端口为待迁移端口的从库。
3.待复制完成,与主库完成同步后,切换所有客户端配置到新的从库的端口。
4.配置从库为新的主库。
5.移除老的端口实例。
6.重复上述过程迁移好所有的端口到指定服务器上。redis单点问题
对应单台redis我们可以使用master/slaver模式,尽量不要出现单点,能够在master机出现宕机的情况下,slaver能够重新接管,继续提供服务。
方案三:代理中间件实现集群
twemproxy是目前使用最为广泛的redis代理中间件,twemproxy将客户端发送过来的请求,进行sharding处理后,转发给相应的redis服务器,客户端不直接访问redis服务器,对客户端来说,后台redis集群是完全透明的。
twemproxy内部处理是无状态的,所以它本身可以很容易的进行集群,防止出现单点故障。twemproxy后台不仅支持redis,还支持memcached。
当然由于使用了中间件代理,相比客户端直接连接服务器,性能上会有一点的影响,性能大概降低了20%-30%左右。
基于Twemproxy的Redis集群方案
方案四:基于Redis的开源分布式服务Codis
Codis是豌豆荚在以上三种方式都不能很好的解决问题的情况下,重新开发的基于Redis的开源分布式服务。
Codis的整体设计:
Pre-sharding slot->[0,1023]
Zookeeper
Proxy无状态
平滑扩展和缩容
扩容对用户透明可以看一张整体的架构图:
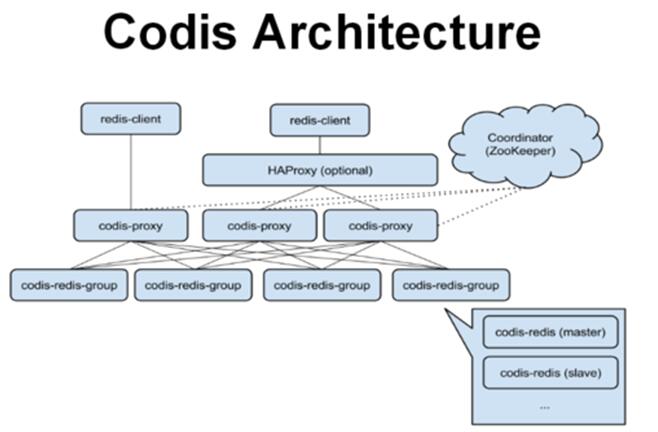
总结:每一种方案都有它适用的环境,也没有哪种方案是可以解决任何问题的,方案往往都是根据我们系统的不断发展不断进行改进的。























































