









入门
1.简介
Kafka is a distributed streaming platform,kafka是一个分布式流式平台,具有三个关键功能:
1.它允许您发布和订阅记录流。在这方面,它类似于消息队列或企业消息系统;
2.它允许您以容错方式存储记录流;
3.它允许您在记录发生时处理记录。
了解几个概念:
1.Kafka作为一个群集在一个或多个服务器上运行;
2.Kafka集群以称为Topic的类别存储记录流;
3.每个记录由一个键,一个值和一个时间戳组成。
来自Kafka官网的一张介绍Kafka的图片:
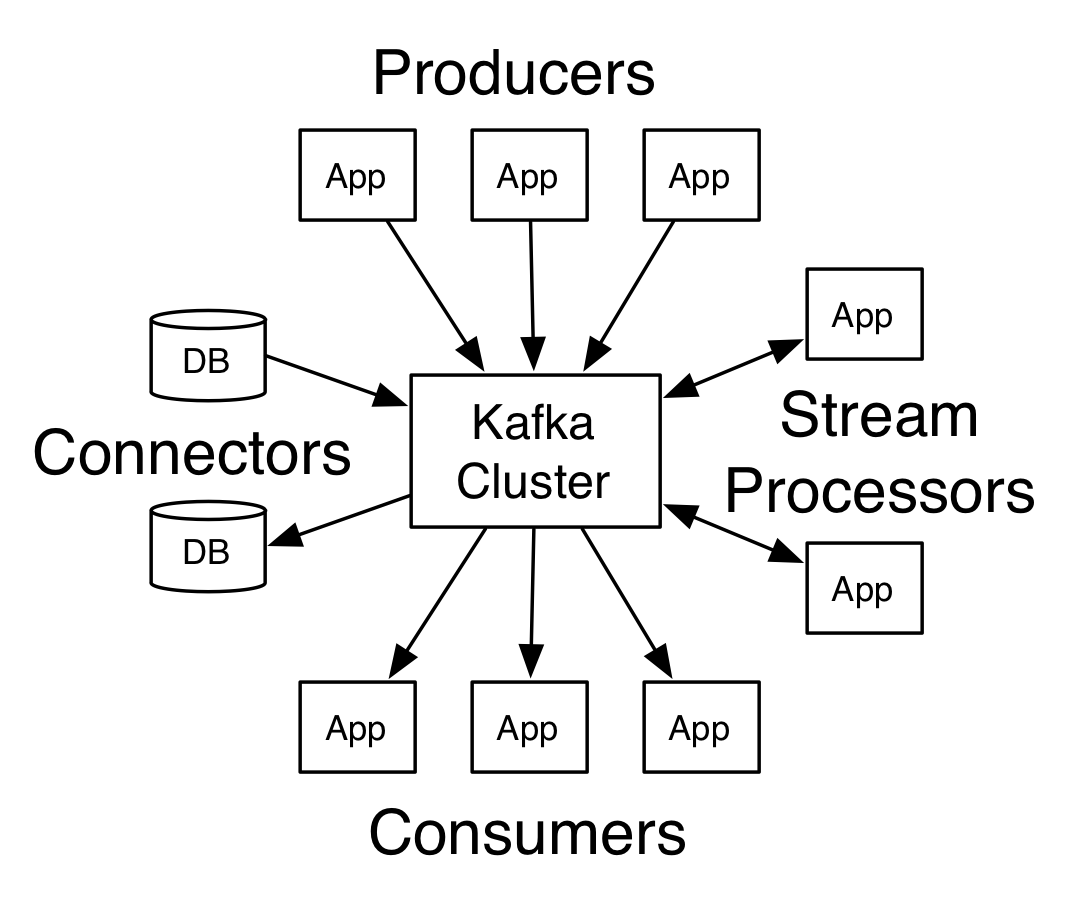
如上图所示,kafka提供了四个核心的API:
1.Producer API允许应用程序将流记录发布到一个或多个Kafka topics;
2.Consumer API允许应用程序订阅一个或多个topics,并处理为其生成的记录流;
3.Streams API允许应用程序充当流处理器,消耗来自一个或多个topics的输入流并产生到一个或多个输出topics的输出流,有效地将输入流转换为输出流;
4.Connector API允许构建和运行可重用的生产者或消费者,将Kafka topics连接到现有应用程序或数据系统。例如,关系数据库的连接器可能捕获对表的每个更改。
2.Topics and Logs
Topics是发布记录的类别或Feed名称,Topics可以具有零个,一个或多个订阅它的consumers,对于每个Topic,Kafka集群维护一个partition(分区)日志,如下图所示:
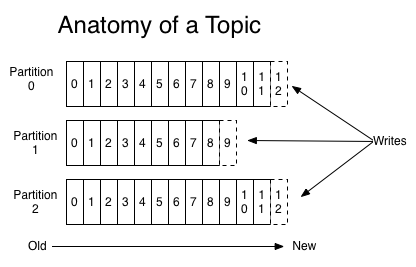
每个partition是一个有序的,不可变的记录序列,不断地附加到结构化提交日志。每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。
Kafka集群保留所有已发布的记录,不论它们是否已经被消费;日志文件会根据保留策略中配置的时间之后进行删除,比如log文件保留2天,那么两天后文件会被清除,无论其中的消息是否被消费。kafka通过这种简单的手段,来释放磁盘空间,以及减少消息消费之后对文件内容改动的磁盘IO开支。
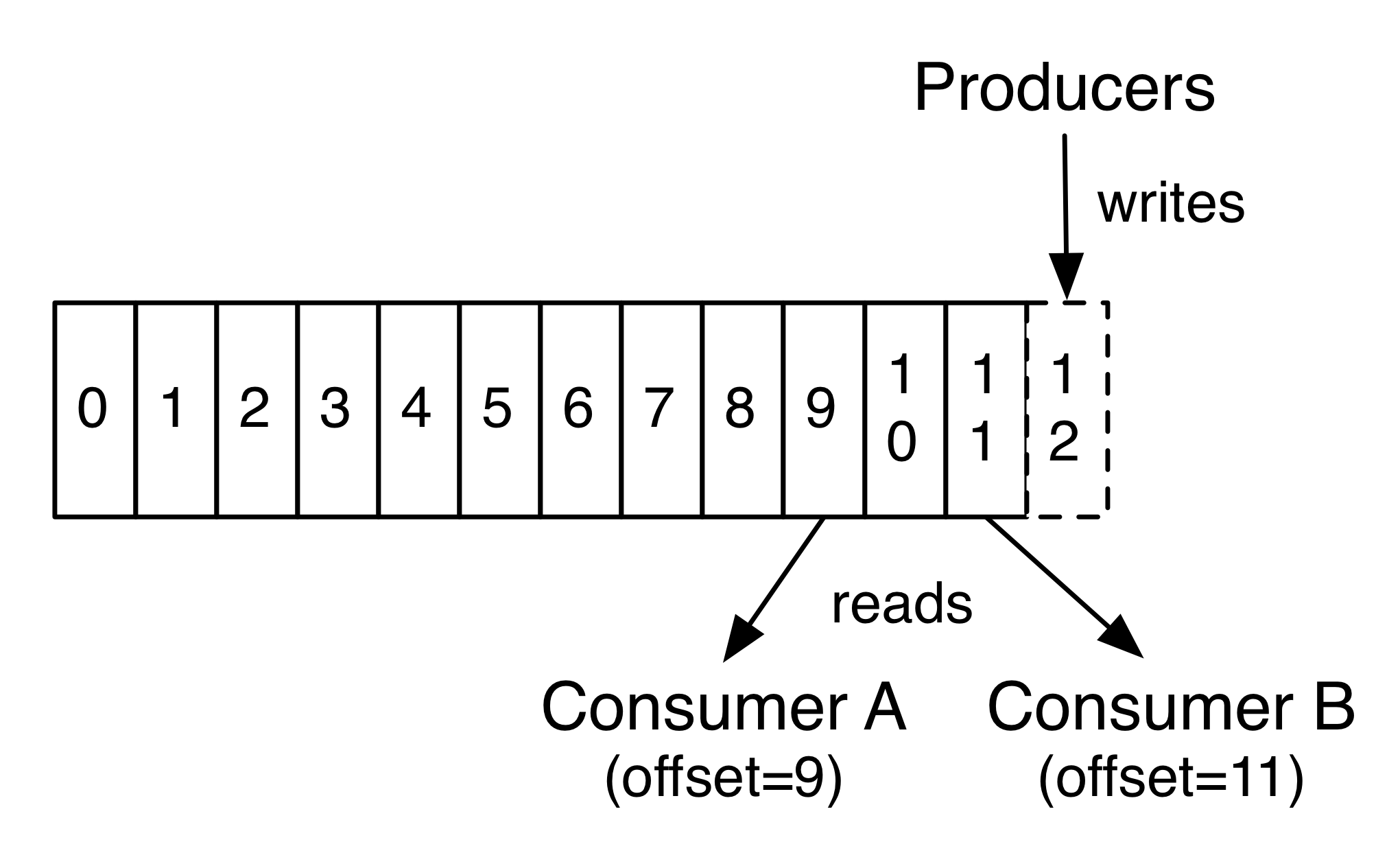
每个消费者保留的唯一元数据是消费者在日志中的offset or position。这种偏移由消费者控制,可以按照喜欢的任何顺序来消费记录。例如,消费者可以重置到较旧的偏移以重新处理来自过去的数据或者跳到最近的记录并开始从“Now”消费。
Kafka的consumer是非常轻量级的,他们可以来来去去,对群集或其他消费者没有太大的影响。
日志中的分区有几个目的。首先,它们允许日志扩展到适合单个服务器的大小。每个单独的分区必须适合托管它的服务器,但一个主题可能有许多分区,因此它可以处理任意数量的数据。第二,它们作为并行性的单位。
3.Distribution
日志的partition分布在Kafka集群中的服务器上,每个服务器处理数据并请求共享分区。每个分区都跨越可配置数量的服务器进行复制,以实现容错。
每个partition具有用作“Leader”的一个服务器和充当“follower”的零个或多个服务器。Leader处理partition的所有读取和写入请求,而follower被动地复制Leader。如果Leader失败,其中一个follower将自动成为新的Leader。每个服务器作为其一些partition的Leader和为其他partition的follower,所以负载在集群内是平衡的。
4.Producers
Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于”round-robin”方式或者通过其他的一些算法等。
5.Consumers
Consumers使用consumer group名称标记自己,并且发布到topic的每个记录都会传递到每个订阅consumer group组中的一个Consumer实例。Consumer实例可以在单独的进程中或在单独的机器上。
如果所有Consumer实例具有相同的consumer group,则记录将有效地在Consumer实例上进行负载平衡。
如果所有Consumer实例具有不同的consumer group,则每个记录将被广播到所有Consumer进程。

一个partition中的消息只会被group中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息;kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的,从Topic角度来说,消息不是有序的。
6.Guarantees
kafka做了如下三个保证:
1.发送到partitions中的消息将会按照它接收的顺序追加到日志中;
2.消费者实例按记录存储在日志中的顺序查看记录;
3.对于具有复制因子N的主题,我们将允许最多N-1个服务器故障,而不会丢失提交到日志的任何记录。
快速开始
1.解压进入目录
tar -zxvf kafka_2.10-0.10.1.1.tgz
cd kafka_2.10-0.10.1.12.配置启动Zookeeper
配置Zookeeper启动文件conf/zookeeper.properties
dataDir=/tmp/zookeeper
clientPort=2181
maxClientCnxns=0启动Zookeeper
./bin/zookeeper-server-start.sh config/zookeeper.properties2.配置启动kafka
配置kafka启动文件config/server.properties
broker.id=0
delete.topic.enable=true
listeners=PLAINTEXT://192.168.111.130:9092
log.dirs=/tmp/kafka-logs-0
zookeeper.connect=192.168.111.130:2181启动kafka
./bin/kafka-server-start.sh config/server.properties &3.创建Topic
./bin/kafka-topics.sh --create --zookeeper 192.168.111.130:2181 --replication-factor 1 --partitions 1 --topic test结果:
Created topic "test".创建一个名为“test”的Topic,其中包含一个分区和一个副本
运行list topic命令
./bin/kafka-topics.sh --list --zookeeper 192.168.111.130:2181结果:
test列出当前有哪些Topic,结果显示刚刚创建的Test Topic
4.发送消息
>./bin/kafka-console-producer.sh --broker-list 192.168.111.130:9092 --topic test
this is a message运行producer,发送消息到服务器
5.启动consumer
>./bin/kafka-console-consumer.sh --bootstrap-server 192.168.111.130:9092 --topic test --from-beginning
this is a message命令行consumer,将消息转储到标准输出
6.配置kafka集群
首先需要将config/server.properties拷贝2份
cp config/server.properties config/server1.properties
cp config/server.properties config/server2.properties然后分别进行配置文件修改,修改结果如下:
//server1
broker.id=1
delete.topic.enable=true
listeners=PLAINTEXT://192.168.111.130:9093
log.dirs=/tmp/kafka-logs-1
zookeeper.connect=192.168.111.130:2181
//server2
broker.id=2
delete.topic.enable=true
listeners=PLAINTEXT://192.168.111.130:9094
log.dirs=/tmp/kafka-logs-2
zookeeper.connect=192.168.111.130:2181修改broker.id用来唯一标识每个节点,同时修改各自监听的端口以及log.dirs存放路径
启动kafka集群
./bin/kafka-server-start.sh config/server.properties &
./bin/kafka-server-start.sh config/server1.properties &
./bin/kafka-server-start.sh config/server2.properties &创建一个新的Topic,并且指定replication-factor为3
./bin/kafka-topics.sh --create --zookeeper 192.168.111.130:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
运行”describe topics”命令
./bin/kafka-topics.sh --describe --zookeeper 192.168.111.130:2181 --topic my-replicated-topic
结果如下:
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
PartitionCount:1和ReplicationFactor:3分别是创建topic指定的分区数和备份数
下面一行指定了Topic名称为my-replicated-topic的broker.id=0分区的信息,如果有多个分区,会出现多行;
Leader是指负责这个分区所有读写的节点;Replicas是指这个分区所在的所有节点(不论它是否活着);Isr是Replicas的子集,代表存有这个分区信息而且当前活着的节点。
注:Partition,Leader,Replicas以及Isr指定的值对应的是broker.id
发送消息
>./bin/kafka-console-producer.sh --broker-list 192.168.111.130:9092 --topic my-replicated-topic
my test message 1
^C启动consumer
>./bin/kafka-console-consumer.sh --bootstrap-server 192.168.111.130:9092 --from-beginning --topic my-replicated-topic
my test message 1
^C通过describe topics命令知道了Leader=1,也就是server1,将它kill掉
> ps aux | grep server-1.properties
root 25270 3.0 21.7 2113532 219548 pts/1 Sl
> kill -9 25270运行”describe topics”命令
./bin/kafka-topics.sh --describe --zookeeper 192.168.111.130:2181 --topic my-replicated-topic结果如下:
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
此时Leader以及换成了broker.id=2,并且Isr中去掉了broker.id=1
再次启动consumer
>./bin/kafka-console-consumer.sh --bootstrap-server 192.168.111.130:9092 --from-beginning --topic my-replicated-topic
my test message 1
^C消息仍然可用于消费,即使之前的Leader以及down
测试log4j写入kafka
1.准备一个工程,然后通过KafkaLog4jAppender忘kafka中写数据
maven:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.10.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-log4j-appender</artifactId>
<version>0.10.1.1</version>
</dependency>其中kafka-log4j-appender用来支持log4j写入kafka
log4j.properties
log4j.rootLogger=INFO,console,kafka
log4j.appender.kafka=org.apache.kafka.log4jappender.KafkaLog4jAppender
log4j.appender.kafka.topic=my-replicated-topic
log4j.appender.kafka.brokerList=192.168.111.130:9092, 192.168.111.130:9093, 192.168.111.130:9094
log4j.appender.kafka.compressionType=none
log4j.appender.kafka.syncSend=true
log4j.appender.kafka.layout=org.apache.log4j.PatternLayout
log4j.appender.kafka.layout.ConversionPattern=%d [%-5p] [%t] - [%l] %m%n
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d [%-5p] [%t] - [%l] %m%nApp类
import org.apache.log4j.Logger;
public class App {
private static final Logger LOGGER = Logger.getLogger(App.class);
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
LOGGER.info("Kafka Test [" + i + "]");
Thread.sleep(1000);
}
}
}2.启动consumer
>./bin/kafka-console-consumer.sh --zookeeper 192.168.111.130:2181 --topic my-replicated-topic --from-beginning
3.运行App程序,观察consumer的输出,结果如下:
2017-01-19 14:45:53,467 [INFO ] [main] - [com.kafkaTest.App.main(App.java:11)] Kafka Test [0]
2017-01-19 14:45:54,745 [INFO ] [main] - [com.kafkaTest.App.main(App.java:11)] Kafka Test [1]
2017-01-19 14:45:55,751 [INFO ] [main] - [com.kafkaTest.App.main(App.java:11)] Kafka Test [2]
2017-01-19 14:45:56,774 [INFO ] [main] - [com.kafkaTest.App.main(App.java:11)] Kafka Test [3]
2017-01-19 14:45:57,789 [INFO ] [main] - [com.kafkaTest.App.main(App.java:11)] Kafka Test [4]
2017-01-19 14:45:58,790 [INFO ] [main] - [com.kafkaTest.App.main(App.java:11)] Kafka Test [5]
2017-01-19 14:45:59,805 [INFO ] [main] - [com.kafkaTest.App.main(App.java:11)] Kafka Test [6]
2017-01-19 14:46:00,820 [INFO ] [main] - [com.kafkaTest.App.main(App.java:11)] Kafka Test [7]
2017-01-19 14:46:01,835 [INFO ] [main] - [com.kafkaTest.App.main(App.java:11)] Kafka Test [8]
2017-01-19 14:46:02,850 [INFO ] [main] - [com.kafkaTest.App.main(App.java:11)] Kafka Test [9]
参考
https://kafka.apache.org/intro
https://kafka.apache.org/quickstart





















































