









协程
协程(coroutine)最早由Melvin Conway在1963年提出并实现,一句话定义:协程是用户态的轻量级的线程
线程和协程
线程和协程经常被放在一起比较;线程一旦被创建出来,编写者是无法决定什么时候获得或者放出时间片的,是由操作系统进行统一调度的;而协程对编写者来说是可以控制切换的时机,并且切换代价比线程小,因为不需要进行内核态的切换。
协程避免了无意义的调度,由此可以提高性能,但也因此,程序员必须自己承担调度的责任,同时,协程也失去了标准线程使用多CPU的能力, 但是可用通过多个(进程+多协程)模式来充分利用多CPU。
协程另外一个重要的特点就是:协程是作用在用户态,操作系统内核对于协程是毫无感知的,这样一来,协程的创建就类似于普通对象的创建,非常轻量级,从而使你可以在一个线程里面轻松创建数十万个协程,就像数十万次函数调用一样。可以想象一下,如果是在一个进程里面创建数十万个线程,结果该是怎样可怕。
进程、线程、协程
进程:拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度。
线程:拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度(标准线程是的)。
协程:和线程一样共享堆,不共享栈,协程由程序员在协程的代码里显示调度。
对协程的支持
Lua, Go,C#等语言原生支持协程
Java依赖第三方库,例如最为著名的协程开源库Kilim
C标准库里的函数setjmp和longjmp可以用来实现一种协程。
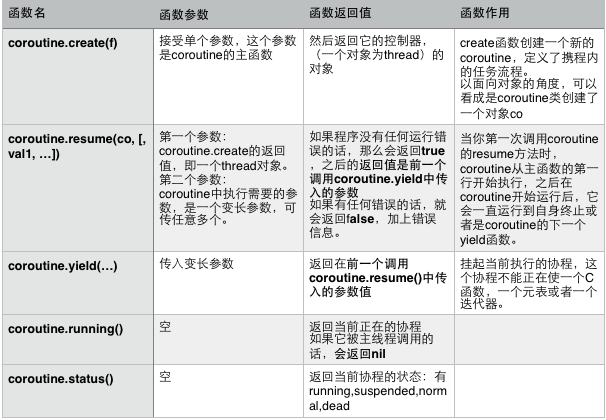
下面以lua语言为例子了解一下协程的工作机制
function foo(a)
print("foo", a)
return coroutine.yield(2 * a)
end
co = coroutine.create(function ( a, b )
print("co-body_01", a, b)
local r = foo(a + 1)
print("co-body_02", r)
return "end"
end)
print("---main---", coroutine.resume(co, 1, 10))
print("---main---", coroutine.resume(co, "r7"))运行结果:
D:\>luac text.lua
D:\>lua luac.out
co-body_01 1 10
foo 2
---main--- true 4
co-body_02 r7
---main--- true end主要利用resume和yield两个函数进行控制切换的时机,具体描述看如下图(来源网上):
协程经常被用在遇到io阻塞操作的时候,直接yield让出cpu,让下面的程序可以继续执行,等到操作完成了再重新resume恢复到上一次yield的地方;有没有觉得这种模式和我们碰到过的异步回调模式有点类似,下面可以进行一个对比。
协程和callback
协程经常被用来和callback进行比较,因为都实现了异步通信的功能;下面以一个具体的场景来描述2者的区别:
A首先要走到B的面前,到B的面前之后,A对B说“Hello”,A说完之后B对A说“Hello”,注意这里的每个动作之前都有一段的延迟时间
这个场景如果用callback的方式来描述的话,会是这样:
A.walkto(function ( )
A.say(function ( )
B.say("Hello")
end,"Hello")
end, B)这边只用到2层嵌套,如果再多几层的话,真是非人类代码了,如果用协程来实现:
co = coroutine.create(function ( )
local current = coroutine.running
A.walto(function ( )
coroutine.resume(current)
end, B)
coroutine.yield()
A.say(function ( )
coroutine.resume(current)
end, "hello")
coroutine.yield()
B.say("hello")
end)
coroutine.resume(co)结构清晰了不少,协程让编程者以同步的方式写成了异步大代码;
来源网上的一句总结:让原来要使用异步+回调方式写的非人类代码,可以用看似同步的方式写出来
不管是协程还是callback,本质上其实提供的是一种异步无阻塞的编程模式,下面看看java在这种模式下的尝试:
java异步无阻塞的编程模式
java语言本身没有提供协程的支持,但是一些第三方库提供了支持,比如JVM上早期有kilim以及现在比较成熟的Quasar。但是这里没打算就kilim和quasar框架进行介绍;这里要介绍的是java5中的Future类和java8中的CompletableFuture类。
1.Future使用
ExecutorService es = Executors.newFixedThreadPool(10);
Future<Integer> f = es.submit(() ->{
// 长时间的异步计算
// ……
// 然后返回结果
return 100;
});
//while(!f.isDone())
f.get();虽然Future以及相关使用方法提供了异步执行任务的能力,但是对于结果的获取却是很不方便,只能通过阻塞或者轮询的方式得到任务的结果。
这种模式暂且叫它伪异步。其实我们想要的是类似Netty中这种模式:
ChannelFuture future = bootstrap.connect(new InetSocketAddress(host, port));
future.addListener(new ChannelFutureListener()
{
@Override
public void operationComplete(ChannelFuture future) throws Exception
{
if (future.isSuccess()) {
// SUCCESS
}
else {
// FAILURE
}
}
});操作完成时自动调用回调方法,终于在java8中推出了CompletableFuture类
2.CompletableFuture使用
CompletableFuture提供了非常强大的Future的扩展功能,可以帮助我们简化异步编程的复杂性,提供了函数式编程的能力,可以通过回调的方式处理计算结果,并且提供了转换和组合CompletableFuture的方法。这里不想介绍更多CompletableFuture的东西,想了解更多CompletableFuture介绍,看一个比较常见的使用场景:
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(耗时函数);
Future<Integer> f = future.whenComplete((v, e) -> {
System.out.println(v);
System.out.println(e);
});
System.out.println("other...");CompletableFuture真正的实现了异步的编程模式
总结
为什么协程在Java里一直那么小众,Java里基本上所有的库都是同步阻塞的,很少见到异步无阻塞的。而且得益于J2EE,以及Java上的三大框架(SSH)洗脑,大部分Java程序员都已经习惯了基于线程,线性的完成一个业务逻辑,很难让他们接受一种将逻辑割裂的异步编程模型。
个人博客:codingo.xyz






















































