









自从谷歌的 Gemini 1.5 Pro 发布后,行业内就有不少人在背后“蛐蛐” RAG。
一方面是因为,Gemini 的表现确实亮眼。根据官方发布的技术报告,Gemini 1.5 Pro 能够稳定处理高达100万 token,相当于1小时的视频、11小时的音频、超过3万行代码或70万个单词,处理极限为1000万 token,相当于《指环王》三部曲,创下了最长上下文窗口的纪录。
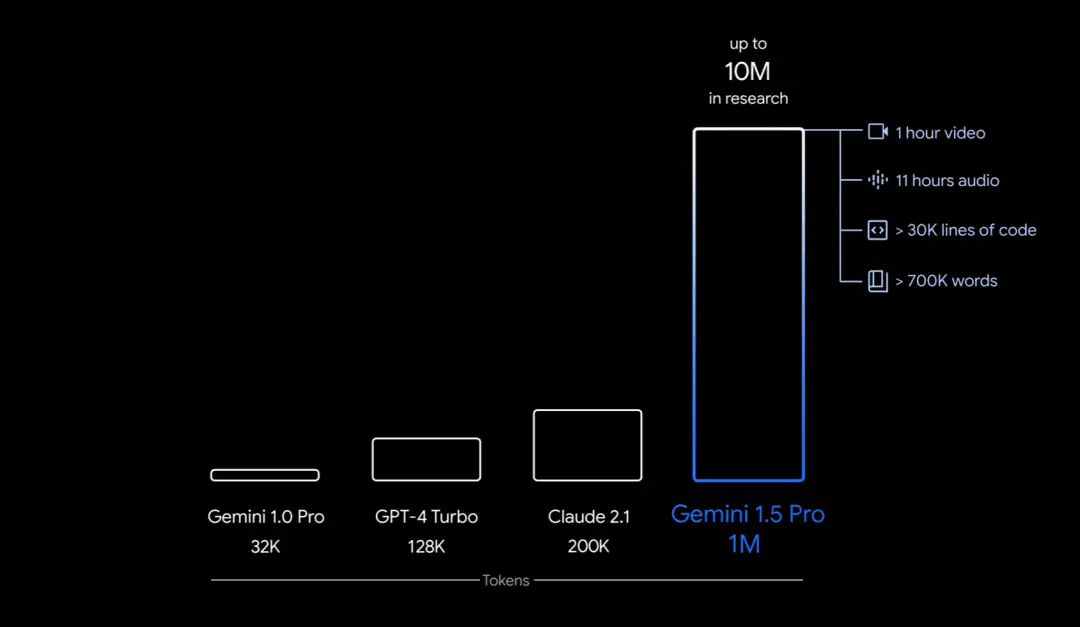
凭借超长上下文理解能力,Gemini 1.5 Pro 得到了很多用户的认可。很多测试过 Gemini 1.5 Pro 的人更是直言,这个模型被低估了。有人尝试将从 Github 上下载的整个代码库连同 issue 都扔给 Gemini 1.5 Pro,结果它不仅理解了整个代码库,还识别出了最紧急的 issue 并修复了问题。
当然,除了谷歌在卷“上下文长度”,其他大模型公司也都在卷这个能力。去年下半年,GPT-3.5上下文输入长度从4千增长至1.6万 token,GPT-4 从8千增长至3.2万 token;OpenAI 最强竞争对手 Anthropic 一次性将上下文长度打到了10万 token;LongLLaMA 将上下文的长度扩展到25.6万 token,甚至更多。
在国内,刚刚完成8亿美元融资的 AI 大模型公司月之暗面,也把“长文本(Long Context)”当前主打的技术之一。去年10月,当时月之暗面发布了首个模型 Moonshot 和 Kimi 智能助手,支持 20 万字的输入。
那么,上下文到底意味着什么,为什么大家都在卷这个能力?
01 上下文长度,大模型好用的关键
上下文技术,是指模型在生成文本、回答问题或执行其他任务时,能够考虑并参照的前置文本的数量或范围,是一种大模型信息量处理能力的评价维度。用通俗的话来说,如果参数规模大小比喻成模型的计算能力,那么上下文长度更像是模型的“内存”,决定了模型每轮对话能处理多少上下文信息,直接影响着AI应用的体验好坏。
比如,随着上下文窗口长度的增加,可以提供更丰富的语义信息,有助于减少 LLM 的出错率和「幻觉」发生的可能性,用户使用时,体验能提升不少。
在业内人士看来,上下文长度增加对模型能力提升意义巨大。用 OpenAI 开发者关系主管 Logan Kilpatrick 话说,“上下文就是一切,是唯一重要的事”,提供足够的上下文信息是获得有意义回答的关键。
02 这跟 RAG 有啥关系?
RAG,中文翻译过来就是检索增强生成,所做的事情并不复杂,就是通过检索获取与用户输入相关的知识并在上下文中提供给大模型,为大模型提供更多更有效的信息,增强生成内容的质量。
具体来说,在语言模型生成答案前,RAG 先从广泛的文档数据库中检索相关信息,然后利用这些信息来引导生成过程,极大地提升了内容的准确性和相关性。
举个例子,作为一名员工,你可以直接问大模型“我们公司对迟到有什么惩罚措施?”,在没有读过《员工手册》的情况下,大模型没有办法回答。但是,借助 RAG 方法,我们可以先让一个检索模型到《员工手册》里去寻找最相关的几个答案,然后把你的问题和它找到的相关答案都送到生成模型中,让大模型生成答案。这就解决了之前很多大模型上下文窗口不够大(比如容不下《员工手册》)的问题。
不过嘛,现在情况不一样了。如果一个模型可以直接处理 1000 万 token 的上下文信息,还有必要再通过额外的检索步骤来寻找和整合相关信息吗?用户可以直接将他们需要的所有数据作为上下文放入模型中,然后像往常一样与模型进行交互。「大型语言模型本身已经是一个非常强大的检索器,为什么还要费力建立一个弱小的检索器,并在分块、嵌入、索引等方面耗费大量工程精力呢?」爱丁堡大学博士生符尧评论道。
那么,RAG 技术是否已经过时了?它是会被长文本彻底取代,还是维持配角现状,还是跟大模型共同进化?
为此,我们采访了 PingCAP AI Lab 的数据科学家孙逸神,以下为他的看法——
03 上下文窗口与 RAG 共存共赢
我认为,在假定 LLM 有足够的阅读理解能力的前提下,RAG 的本质就是在上下文窗口的约束下,提高 Prompt 的有效信息密度,从而提高生成质量的有力手段。而这两者,是毫无冲突的。
是的,我认为上下文跟 RAG 并不矛盾。GPT-4o 的回答,基本上表达了我的观点:
Q: LLM 的 context window 和 RAG 有什么关系吗?
A: LLM(大型语言模型)的 context window 和 RAG(Retrieval-Augmented Generation)是两个相关但不同的概念。它们在信息处理和生成方面有着不同的作用和机制。
首先来看看他们各自的应用场景和具体作用:
Context Window,指大型语言模型在一次生成或处理过程中能够看到和使用的文本长度。注意,它是有长度限制的。例如,GPT-4 的 context window 可能是 8,000 或 32,000 个 token(具体长度取决于模型的版本)。
在这个窗口内,模型可以使用上下文信息来理解和生成文本。如果超出上下文窗口限制,模型就无法利用所有相关信息,可能会导致直接报错退出。
所以,context window 是任何任务的约束条件,即大模型单次最多能读的内容量,模型在处理当前任务时依赖于它能看到的上下文。
Retrieval-Augmented Generation,一种结合检索和生成的技术,旨在提高生成文本的质量和信息性。
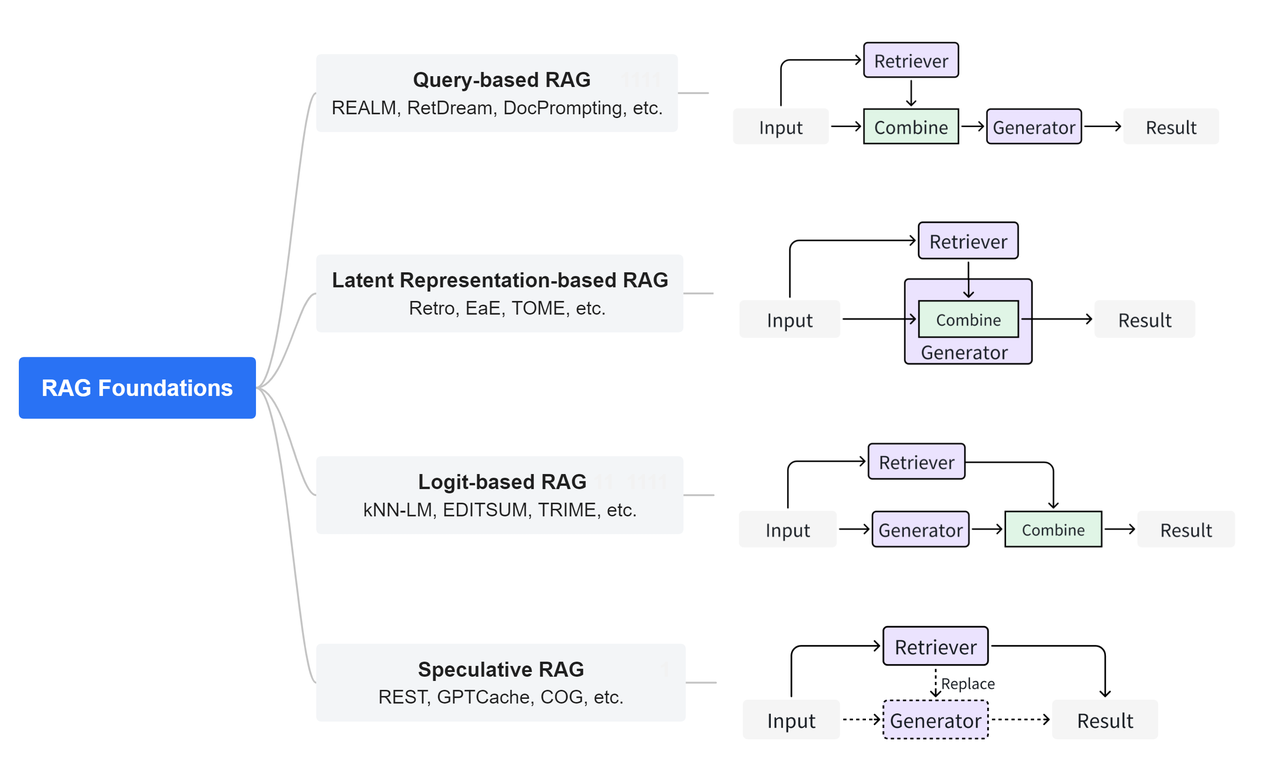
图源:https://github.com/hymie122/RAG-Survey
在检索阶段,RAG 系统首先从一个大规模的知识库或文档数据库中检索出与查询相关的信息。这通常使用信息检索技术,例如 BM25、TF-IDF 或基于深度学习的检索模型(如 Dense Passage Retrieval, DPR);当然,也可以是向量检索,总而言之,检索并不限定某一种特定方法,甚至可以多种方法进行组合。
在生成阶段,RAG 系统会把检索到的相关文档或信息作为上下文的一部分提供给生成模型,生成模型使用这些上下文来生成更准确和相关的回答。另外,通过使用检索到的外部信息,RAG 能生成更具信息性的回答,特别是在模型本身知识库不足或需要实时信息时。这就是结合上下文生成和增强生成。
那它们俩之间有啥关系?
-
增加有效信息输入:
RAG 技术可以在上下文窗口以内,增加有效消息量。LLM 的 context window 有限,但通过检索相关文档并将其作为上下文传递给生成模型,可以在不直接增加模型 context window 的情况下提供更多的相关信息。
-
提高准确性:
当需要生成具体领域或最新的信息时,RAG 的检索机制可以提供精确的上下文,帮助 LLM 生成更准确的回答。这样可以弥补模型训练时的数据不足或过时的问题。
所以,LLM 的 context window 和 RAG 在生成文本时都有重要作用,但它们通过不同的方式来增强文本生成的质量和连贯性。context window 提供了模型在单次处理中的上下文范围,而 RAG 通过检索相关信息提高了上下文的信息质量,使得模型可以生成更为信息丰富和准确的内容。
04 未来,RAG 也不会被取代
我认为,与其聚焦于现下讨论它们之间的优劣势,不妨以发展的眼光来看 LLM 和 RAG 的关系。
从 OpenAI 推出 ChatGPT 开始,人们体验到了碾压以往同类“智障聊天机器人”的 AI 产品。ChatGPT 引爆全球以后,大家发现了它巨大潜力的同时,也同样发现了它很多的能力缺陷,其中首当其冲的就是幻觉。另外,上下文有限也限制了应用的想象力。
如何减轻幻觉?一种方式是重新训练基础模型,用更多更高质量的语料,费人费时费能费钱。于是人们又使用了微调的方法,用相对少的训练量,修改部分深度网络的参数,来达到质量提升的效果。它的性价比已经是小团队或个人开发者可以接受的状态了。
但为什么还会继续发展到 RAG 呢?其中一方面原因是微调依然需要对语料的质量有要求,虽说微调本身不花太长时间,但是语料的收集和前处理是需要一定时间的;另一方面还有一个原因是,无论是训练还是微调,大方向上看是总体提升的,但是期待没有一个点变弱也是不太可控的,它可以定向地学习好的,但是难以定向地遗忘不好的,所以是存在变差的可能性的。
于是,RAG 也很自然地成为大家提高输出质量的一个研究方向。RAG 能起到作用,本身隐含了一个前提条件,就是 LLM 在上下文窗口内存在较强的“阅读理解”能力。虽说我依然不认为 LLM 有“逻辑”能力(为什么 LLM 看起来是有“逻辑”的,因为“逻辑”的最大载体是语言,如果 LLM 输入“学习”的是大量蕴含正确逻辑的文本,那它作为一个类似马尔科夫决策过程,它的生成也会倾向于有“逻辑”的输出,但这不等于理解“逻辑”并能自如地运用“逻辑”),但它确实在绝大多数情况下表现出了优秀的“阅读理解”能力以及续写和回答问题的能力。
既然这个前提在广泛的实践上被证实大体有效,那人们可以很自然地想到一个降低 LLM 幻觉,改善 LLM 输出质量的方法。第一,更充分地利用上下文窗口的长度。这和人类间的交互是类似的,就像提问的智慧一样,给予更多的信息,通常对于生成的内容是有帮助的。如果输入内容的有效信息密度提高,同样也是有益的。这一点很容易直观地理解。
那接下来,如何提高上下文窗口限制内的有效信息密度,第一种方式就是人工提供。就是一开始大家钻研玩花的 Prompt 魔法。
但每次手工输入在工程上是没法 Scale 的,所以上述方式更多是对直接使用 Chat 的终端用户有价值,对于要包装 LLM 为用户提供更好服务的中间商是不太可行的,于是 RAG 自然就出现了。如果你把它理解成搜索引擎,就是在上下文窗口长度限制内,增加更多与用户输入“相关”的内容。提供的内容越多,通常 LLM 自由发挥天马行空的概率就会降低,这也是很朴素的一个结论。RAG 就是一个尽可能提高有效信息密度的工程实现手段。
到这里,其实主要的观点——上下文窗口与 RAG 没有任何矛盾的结论已经可以支撑住了。
进一步补充说明的话,RAG 整个系统的目的还是 Generation,Retrieval 是一种提高质量 (Augmented) 的手段,上下文窗口是 Generation 子系统的一个参数或者说约束,Retrieval 是在这个约束内工作的,属于是带着镣铐跳舞的状态。窗口小就少 Retrieving 一些东西回来,窗口大就多 Retrieving 一些东西回来,就是这么一个朴素的逻辑。
而上下文的拓展本身,与需要表达的观点无关,需要关注的是,趋势上来看,上下文越长,LLM 的能力会相应变弱,这是符合直觉的,人类也有同样的问题。第二是上下文拓展的方法,这个在 LLAMA 上研究得已经很多了。开发 LLM 的人目标一定是更长的上下文且不断提高在此前提下的输出质量。
另外要补充说明的一个角度是,LLM 在不断地进步,很多早期通过包装 LLM 来为用户提供价值的中间商被上游新一代的 LLM 直接降维打击出局,所以围绕 LLM 做开发的人都不免要担心自己在做的事情,会不会被下一代 LLM 干掉,这是一个很现实的问题。我的观点是 RAG 不会,Agent 也不太会(此处不展开)。RAG 能够长期立足的原因在于,训练和微调之间是有时间差的,这个时间差会变小,但长期来看,不会变为 0,在这个时间差以内的信息,只能通过 RAG 的方式注入。同样的,私域知识也只可能通过 RAG 的方式注入。时效性需求和私有性需求决定了 RAG 会一直存在,大家要做的只是进一步提高 RAG 的搜索质量,让 LLM 可以更好地为用户所爱。
作者:
孙逸神
PingCAP AI Lab Data Scientist.自 ChatGPT 震撼发布至今,聚焦 LLM 应用开发及 Multi-Agents 等应用方向的探索,开发了 TiDB Bot、LinguFlow 等应用,并参与 AutoGen 社区开发。






















































