









通常来说,序列化json,实际上有2总方式
- 通过当前流行的JSON工具。
- 编写代码,手工序列化
这俩种方式各有优劣。第一种方式毫无疑问,不需要开发者做什么工作,直接调用序列化接口,输出就是json。但是,如果需要特殊需求,比如需要将日期格式化按照yyyy-mm-dd 输出,这些JSON工具可以指定日期格式化输出,比如FastJSON里:
SerializeConfig mapping = new SerializeConfig();
String dateFormat = "yyyy-MM-dd";
mapping.put(Date.class, new SimpleDateFormatSerializer(dateFormat));
String json = JSON.toJSONString(obj,mapping);在Jackon里,代码也是类似,如:
ObjectMapper objectMapper = new ObjectMapper();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
objectMapper.setDateFormat(sdf);
objectMapper.writeValue(writer, obj);
- 对象里有个字段是Calendar,我想格式化yyyy-MM-dd 输出。
- 对象里另外有个字段也是Calendar,我想仅仅输出time(Long类型)
- 对象及其关联对象的id我都不想输出。
- 如果某个对象的集合属性为null,则仅仅输出[], 但另外一个集合属性未null,则输出null。
当前流行工具总是疲于应付这种“变态”序列化需求,不停的升级版本增加处理类来解决这些需求。有没有终极解决办法吗?
在回答这个问题前,让我们回归到我说的第二种序列化解决方法,就是手工编写代码。通过硬编码貌似是是终极奥义。各种变态序列化需求都能通过硬编码来解决。然而,这种终极奥义的问题是序列化太麻烦了。面对企业应用,互联网应用中成百上千的模型,手工来序列化是不现实的,那么,有没有第三个办法,既能方便序列化对象,有具有很强的序列化能力,应付各种变态需求呢?
以我看来,的确有第三个办法,正如正则表达式那样,能分析各种复杂文本,依靠的是(位置&指令)*。序列化JSON,实际上也需要类似正则表达式的思路,我抽象为(locatoin:action)*. location 可能是指一个对象的属性名,也可能泛指某个类型的对象。action 是指序列化操作,比如忽略此location,或者一个排序动作,一个格式化动作,或者,是一个调用此对象的某个方法的动作等等。对于以下User对象,我们可以指定一系列的(Location:Action)*
public class User{
String name="joel";
int age =12;
double salary=12.32266;
Date bir = new Date();
Customer customer = new Customer();
List<Customer> list = new ArrayList<Customer>();
List<Customer> deleteList = null;
//getter and setter 方法必须有,在此忽略
}
| Location:Action | 描述 |
| name:i |
name 指的是User对象的name属性,i代表一个操作,意思ignore。表示此字段不需要序列化 |
| ~d:f/yyyy-MM-dd/ |
~d 表示所有日期类型(包含其子类),动作是调用一个格式化函数f,参数是yyyy-MM-dd |
| bir:$.getTime |
bir是User对象bir属性,输出时调用其getTime方法输出毫秒时间 |
| ~*::O/name, age/ |
将User类的name,age放到前面优先显示 |
| ~*:Ci/name,id/ |
如果User实例被引用过(循环引用),则仅仅输出id,和name。即避免了循环引用问题,也同时有明确的输出 |
| deleteList :?null->[] |
deleteList是User的属性,如果为null,则输出[] |
如上几个简单例子可以看到基于(Location:Action)序列化功能的强大和灵活,甚至可以 组合Action,比如
~L/java.util.Calendar*/:$.getTime->f/yyyy-MM-dd/,可以解释为对于所有对象类型为java.util.Calendar及其子类,输出的时候,先调用$.getTime,获得Date,然后再格式化输出。
由此可见,如果定义好Location,以及提供一定数量的Action,和内置一些表达式操作(如?empty->dosomething),便具有超过传统的基于(Annotation&&SerializerFeature)的JSON工具的序列化能力。不仅仅如此,通过指定好policy,policy=(location:action)*,可以实现对同一对象的不同序列化策略。比如代码:
String json = JsonTool.serialize(User,"id:i"); //不输出id
//or 指定一个序列化策略,age,name先输出,适合有特殊需求的对象或者无法注解(第三方)对象
String json2 = JsonTool.serialize(User,"~*:O/age,name/"));
由此可见,序列化JSON的第三种道路,即"(Location:Action)*" 非常接近我认为的序列化JSON终极奥义,他具有当前流行"(Annotation&SerializerFeature)*" 操作简便性,也具有硬编码序列化的的灵活性。我写了一个beetl-json 作为验证,断断续续花了2周时间和牺牲了周末:),自我感觉效果不错的,我贴一些Beetl-JSON 代码可以看看
JsonTool.addLocationAction("~d","f/yyyy.MM.dd/");
JsonTool.addLocationAction("~L/java.util.Calendar*/","$.getTime->f/yyyy-MM-dd/");
//类json格式的策略,用逗号分开多个locationAction
JsonTool.addPolicy("~f:f/#.##/,~c:?null->[]");
// 默认是紧凑输出,使用true,将换行和缩进
JsonTool.pretty = true;
//序列化User
String json = JsonTool.serialize(User);
//or 指定一个序列化策略,age,name先输出,适合有特殊需求的对象或者无法注解(第三方)对象
String json2 = JsonTool.serialize(User,"~*:O/age,name/"));
User对象定义如下:
@Json(
policys={
@JsonPolicy(location="name", action="nn/newUserName/"),
@JsonPolicy(location="deleteList", action="?empty->[]")
}
)
public class User{
String name="joel";
int age =12;
double salary=12.32266;
Customer customer = new Customer();
List<Customer> list = new ArrayList<Customer>();
List<Customer> deleteList = null;
//getter and setter 方法必须有,在此忽略
}
序列化性能现在还未完全考虑中,因为只做了2周,功能还不全,还属于验证阶段,此时如果比较性能,比较占便宜,我把我初步的性能测试代码放到 performance test 里了,包含了FastJSON,Jackson.在我老式笔记本里,单线程序列化一个普通对象1百万次,性能如下:
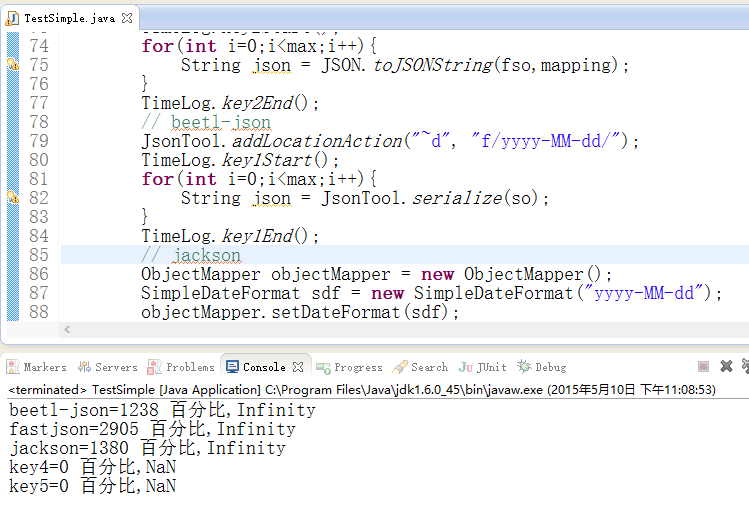
初步性能测试还是不错的。beetl-json略快一些,只需要1.238秒,不过考虑到beetl-json现在功能还未全,且对日期输出做了优化,而FastJson没有做。所以这三个之间,实际没有太大的性能差距。
在当今web应用,互联网应用火爆的年代,Json序列化是这些应用需要的一种基础技术能力,基于(Location:Action)* 的JSON工具,相比于传统(Annotation&SerializerFeature )* 的工具会更加灵活和功能强大,能高度满足程序员的序列化需求。beetl-json会进一步实践这种思想。让天下没有难以序列化的对象






















































