









编者按:您是否曾经遇到这样的情况:明明构建了一个功能强大的 RAG 系统,但用户却频繁抱怨"找不到想要的信息"或"返回的结果不够准确"?这是许多 RAG 应用开发者面临的共同挑战。
这个问题不仅会导致用户体验下降,更可能直接影响 RAG 系统的使用率和实际价值。如果未能得到妥善解决,之前的辛苦工作恐将付之东流,甚至影响整个项目的成功。
这篇文章并非纸上谈兵,而是源自作者在实际项目中的第一手经验。文章详细介绍了 5 种 Query Translation 技术:
a) Step-back prompting:将具体问题转化为更宽泛的问题,以便获取更多上下文信息。
b) HyDE (Hypothetical Document Embedding):利用 LLMs 生成文档,然后基于这个文档检索相关信息。
c) Multi-query:使用 LLMs 根据原始 query 生成多个版本的 query ,以改进基于距离的相似度搜索。
d) RAG-Fusion:与 Multi-query 类似,使用 Reciprocal Rank Fusion 算法对检索结果进行重新排序。
e) Decomposition:将复杂问题分解为多个子问题,分别检索答案后再整合。
这些技术各有优势,在实际应用中可能需要根据实际情况结合使用才能达到最佳效果。
作者 🎨 | Thuwarakesh Murallie
编译 🌺 | 岳扬

Photo by travelnow.or.crylater[1] on Unsplash[2]
若认为用户会每次都向 LLMs 提出完美的问题,那您就大错特错了。与其直接执行用户的 query ,为何不选择优化用户的 query 呢?这就是所谓的 query translation 技术。
我们开发了一款应用,用户可以通过它查询我们公司历史上制作过的所有文档,其中包括PPT、项目提案、进度报告、交付文档和其他各类文档等。这一成果非常了不起,因为过去的许多此类尝试都失败了。多亏了 RAGs,这一次的效果非常好。
在项目演示阶段,我们都对这款应用表现出了极大的热情。最初,我们只针对一小部分员工进行了推广。然而,我们观察到的现象并未让我们感到非常兴奋。
原本以为这款应用会彻底改变大家的工作方式,但大多数用户只是尝试使用了几次便不再使用了,仿佛这款应用只是孩子们的玩具项目一样。
日志数据显示这款应用表现良好,但我们还是与实际使用过该应用的用户进行了交流,以便能够确定问题所在。通过他们的反馈,我们开始思考如何通过 query translation 技术来消除 user inputs 中的歧义。
让我们来看一个具体的例子。
有位用户对我们提供给客户"XYZ"的关于收购与时尚业务相关的企业的建议感兴趣。他输入的问题是:"合作伙伴 XYZ 进行了哪些与时尚业务相关的收购?(What are the fashion-related acquisitions made by XYZ partners?)"该应用程序检索了相关用于交付的 PPT 文件,给出了一份包含十几家公司的清单。但这份清单与用户的期望大相径庭,合作伙伴 XYZ 实际上已经收购了(比如)7家时装品牌,而清单中只列出了4家。这位用户同时也是一名测试人员(tester),他对实际收购的数量了如指掌。
难怪大家会放弃使用这款工具。幸运的是,因为采取了向全体用户逐步推出的策略,我们还有机会挽回失去的信任。
为了解决这一问题,我们对这款应用程序采取了一系列的改进措施。其中一项重要更新就是 query translations 技术。
本文旨在概述我们使用的不同 query translation 技术,而不进行深入的技术解析。例如,这些技术可以与 few-shot prompting(译者注:提供几个示例输入和输出。) 和 chain of thoughts(译者注:鼓励模型在生成最终答案之前,先产生一系列的中间推理步骤。) 等提示词技术相结合,以优化结果。但这些技术细节将留待后续文章[3]中详细讨论。
接下来,我们将逐一研究这些技术。在此之前,先来看一个简单的 RAG 示例。
01 Basic RAG Example
RAG(Retrieval-Augmented Generation)应用都至少会有一个数据库,通常是一个向量数据库(vector store)和一个语言模型(language model)。RAG 的核心概念其实很简单:在大语言模型(LLM)利用其已有知识回答用户问题之前,它会先在数据库中搜索相关的上下文信息,以此来生成更加精确的答案。
下图展示了一个最基础的 RAG 应用示例。
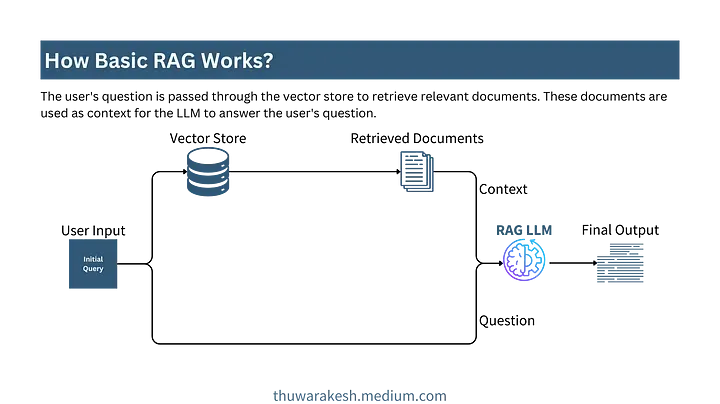
Basic RAG application Workflow --- Image by the author.
在基础的 RAG(检索增强生成)应用中,与大语言模型(LLMs)的交互仅发生一次,可以是 OpenAI 的 GPT 模型[4]、Cohere 模型[5],也可以是您自行部署在本地的模型。
下面给出的代码展示了如何实现上图的 RAG 基础工作流。我们将以此代码为基础,进一步探讨本文中提到的其他技术。

在上述代码中,我们通过一个网页加载器(web-based loader)来获取 Django 的官方文档页面,并将其内容存入 Chroma 向量数据库中。我们可以将这一过程应用于网页文档、本地文本文档、PDF文档等不同类型的数据资源。
在此例中,我们没有采用高级的检索技术,而是直接将检索器整合到了最终的RAG(检索增强生成)流程中。后续我们将使用检索器链(retriever chain)来代替单一的检索器。 文章后续内容将着重讲解如何构建检索器链。
02 Step-back prompting
该技术用于确保生成的答案与上下文背景信息保持一致,不发生冲突。
Step-back prompting 与基本的 RAG 流程非常相似,但在处理用户提出的问题时,不是直接针对用户提出的初始问题进行查询,而是用一个更宽泛的问题从数据库中检索相关文档。
与具体问题相比,更宽泛的问题能捕捉到更多的上下文信息。 因此,大语言模型(LLMs)能够基于这些信息为用户提供更多有用的信息,且不会与整体上下文信息相抵触。
当最初的 query 过于具体和详细,但又缺乏全局视角时,这种方法往往非常有用。
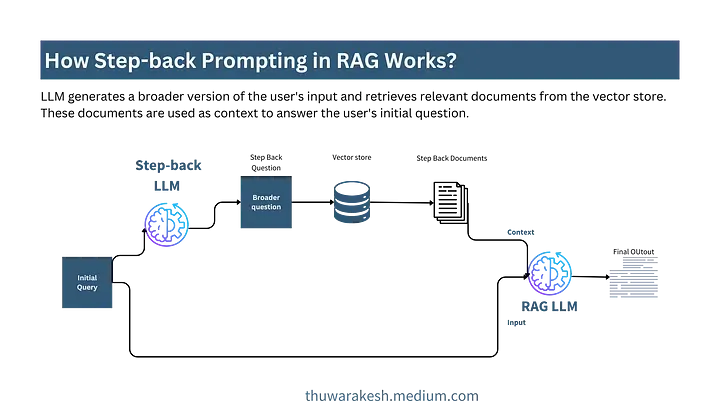
Step-back prompting workflow --- image by the author.
Step-back prompting 的流程是:语言模型先扩展用户输入的 query ,然后从向量数据库中检索相关文档,以此提供必要的上下文,并回答用户最初提出的问题。
下面是 step-back prompting 的代码实现。请注意,我们在这里采用了不同的处理方式,与前文的基本 RAG 流程中直接传递检索器的方法不同。

Step-back prompting 对于那些需要依赖更广泛的上下文背景信息的应用场景极为有用。 通过这种方式,LLMs 能够为相关问题提供前后一致的答案。
03 HyDE (Hypothetical Document Embedding)
给出的答案不仅仅是直接回答问题,而是包含了与问题相关的背景信息或其他相关内容,使得答案更加全面和有深度。还会提供与答案内容相关的可靠信息来源,比如学术文献、研究报告、官方网站等,以便于验证信息的准确性和可靠性。
HyDE(Hybrid Document Embedding)是一种近来流行且广受欢迎的文档检索技术。其核心思想是利用大语言模型(LLMs)的已学习的先验知识(prior knowledge)编写文档,然后使用这个文档从向量数据库中检索或提取相关的上下文信息。
HyDE 特别适用于用户使用通俗的语言描述问题,而向量数据库中的信息却极为专业的情况。 此外,由于 LLMs 生成的文本信息中包含了较多的关键词或关键短语,使得检索到的相关信息更加精准。
例如,对于"提高 Django 性能的10种方法(10 ways to improve Django's performance)"这样的 query ,HyDE 能够提供一个涵盖成本考虑(cost implications)、缓存策略(caching)、数据压缩(compression)等全方位的答案。

HyDE document retrieval process --- image by the author.
下列代码片段是上图的代码实现。这次,我仅提供了使用 HyDE 构建检索器链(retrieval chain)的代码片段。

04 Multi-query
该技术通过改进基于距离的相似度搜索(the distance base similarly search),从而能够检索到更多与用户提出的问题相关的文档,从而提高检索结果的相关性和准确性。
Multi-query 技术有助于解决在基于距离的相似度搜索中可能遇到的问题。大多数向量数据库在检索向量化文档(vectorized documents)时使用余弦相似度(cosine similarity)作为度量标准。只要文档之间的相似度足够高,这种方法一般都能表现良好。 然而,当相似度太低,以至于无法通过基于距离的相似度度量来有效地识别它们之间的关联时,检索过程就可能无法达到预期效果。
在 multi-query 方法中,我们要求大语言模型(LLMs)为同一 query 转换多个版本的 query 。例如, "How to speed up Django apps" 这样的 query 会被转换为另一个版本的 query ------ "How to improve Django-based web apps' performance?"。这些 query 合在一起共同作用,从向量数据库中检索出更多相关的文档。
在将这些文档传递给 RAG-LLM 生成最终回答之前,我们需要对检索到的文档进行去重处理。 因为多个 query 可能会检索到相同的文档。如果传递所有文档,可能会包含重复项,超出 LLM 的 tokens 阈值,从而影响最终的回答质量。
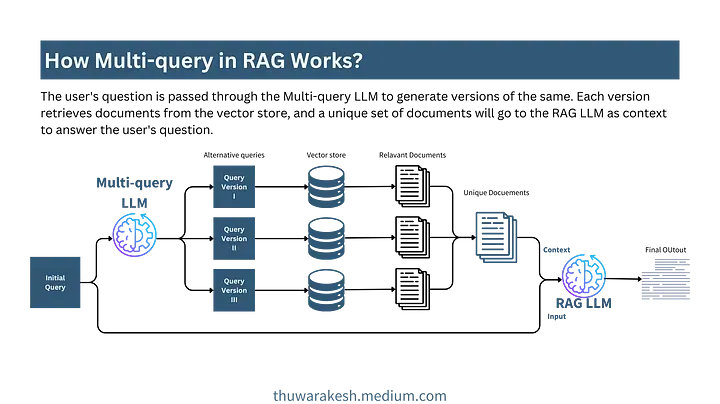
Multi-query retrieval workflow --- image by the author.
下面这个代码片段实现了一个额外的功能,可用于去除文档中的重复项。其余部分与其他方法保持一致。

05 RAG-Fusion
在信息检索和生成答案的过程中,优先考虑和利用与用户提出的问题更相关的文档是非常重要的,因为这些文档提供的信息更有助于生成准确和有用的答案。
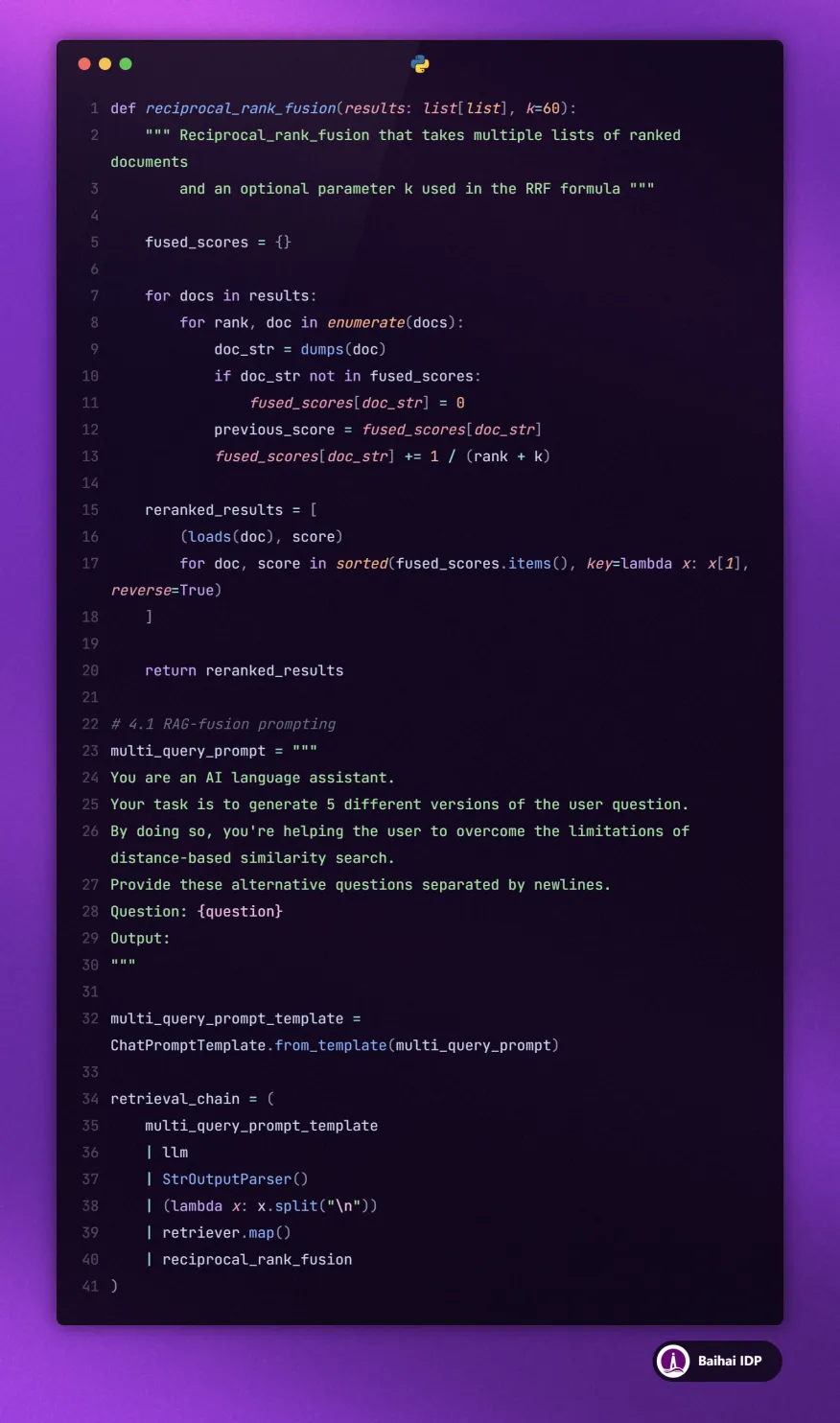
RAG fusion 和 multi-query 在文档检索方面有诸多相似之处。我们在这里再次要求大语言模型(LLM)生成初始 query 的多个不同版本。然后,我们用这些不同版本 query 分别检索相应的文档,并将它们合并。
然而,在合并和去重文档的同时,我们也会根据文档的相关度对它们进行排序。下面是 RAG-fusion 工作流程的示意图。

RAG-fusion workflow --- image by the author.
我们不再只进行去重操作,而是使用排序系统(ranking system)对文档进行排序。Reciprocal fusion ranking(RRF)是一种非常巧妙的文档排序算法。
如果多个版本的 query 检索到的同一文档是最相关的,那么 RRF 算法就会把该文档排在前面。 如果某个文档只在其中一个版本的 query 中出现,且相关度较低,那么 RRF 将把该文档排在较低的位置。 这样,我们就能获得更相关的信息并对其进行优先排序。
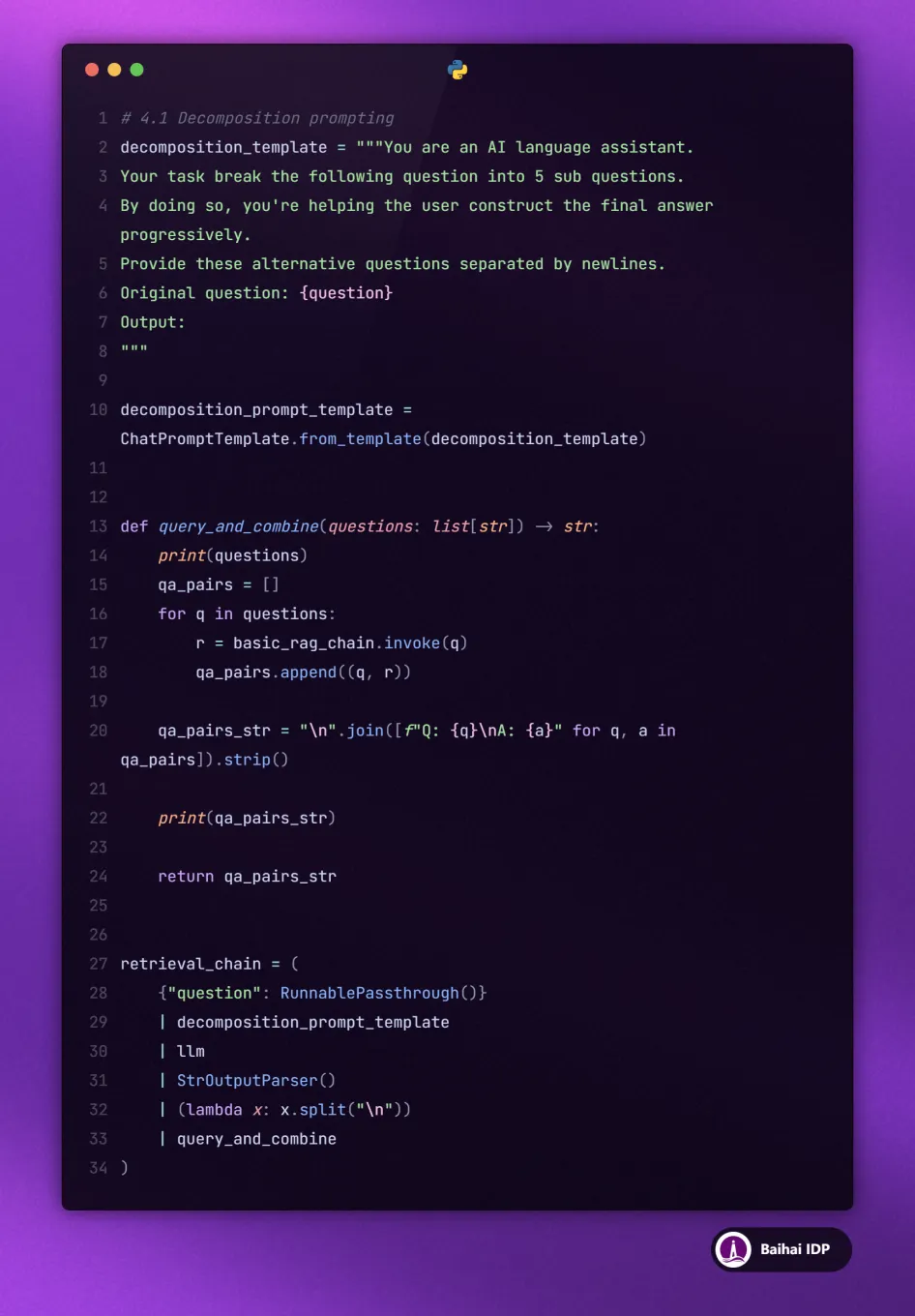
06 Decomposition
在处理复杂问题时,大语言模型(LLM)能够将问题拆分成多个部分,然后逐步构建出答案。
有些情况下,直接给出答案并不是最佳策略。解决复杂任务的高效方法是将问题分解成多个部分,然后逐个部分地回答。
这也不仅仅是 LLMs 独有的技巧,对吗?
是的,我们在分解 query 的过程中试图将初始问题拆分成多个子问题。回答这些子问题的过程中将获得解决初始问题的线索。

Query decomposition in RAG --- image by the author.
如图所示,我们为每个子问题检索相关文档并分别回答。然后,我们将这些问答对(question-and-answer pairs)传递给 RAG-LLM 。然后,LLM 拥有了更多、更详细的信息来解决复杂问题。
07 Final thoughts
这款应用程序从演示版本到部署于生产环境,中间经过了许多优化流程。其中不可避免的一步就是使用 query translation 技术。
我们所解决的问题在复杂程度上也各不相同。必须得考虑用户发送不完美的 query 才是常态。检索过程的缺陷也需要得到解决。 这些都是需要考虑的问题。
要选出哪一种 query translation 技术最佳,并没有唯一正确的方法。在实际应用中,我们可能需要结合多种技术才能获得理想的输出结果。
Thanks for reading!
Hope you have enjoyed and learned new things from this blog!
Thuwarakesh Murallie
Data Science Journalist & Independent Consultant
https://www.linkedin.com/in/thuwarakesh/
END
🔗文中链接🔗
[1]https://unsplash.com/@travelnow_or_crylater?utm_source=medium&utm_medium=referral
[2]https://unsplash.com/?utm_source=medium&utm_medium=referral
[3]https://towardsdatascience.com/advanced-retrieval-techniques-for-better-rags-c53e1b03c183
[4]https://platform.openai.com/docs/models
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:





















































