









文章来源|字节跳动数据科学团队
开源项目地址|https://github.com/bytedance/CausalMatch
CausalMatch 是字节跳动于 2024 年 7 月正式开源的一款基于 Python 的轻量化统计分析工具,主要涵盖了因果推断常用的统计分析方法——匹配(Matching)。它孵化于字节跳动内部,从上线至今支持多个业务线对非实验场景进行策略效果分析的需求。在经历了不断发展和完善的过程后,我们相信 CausalMatch 已经准备好在更多业务场景提供服务,并很高兴的宣布 0.0.1 版本正式发布。
01 背景
因果推断主要研究干预策略如何影响结果,被广泛应用于生物、医学、经济学等各个行业。常用于建立因果关系的方法以随机实验(或 AB 测试)为主,但在互联网行业应用场景中常受限于法务风险或实验可能带来负向营收,导致随机实验并不总是可行,因此需要辅助因果推断的统计方法测算策略效果。
在这种情况下,如何科学的估计策略效应成了数据分析或者数据科学团队的一个挑战。因此我们将日常业务中应用最广泛的因果效应估计方法 —— 匹配,进行了理论梳理,并开发了一套专注于匹配的轻量化因果关系分析工具 CausalMatch,为使用该方法来做决策分析的业务场景构建一套流程性且规范化的分析框架。
02 项目介绍
CausalMatch 主要通过匹配解决样本偏差,而样本偏差中最常见的问题是自选择偏差(self-selection)。在电商业务中一个常见的有自选择偏差的场景是:运营鼓励商家报名某活动并且给予一定的扶持,而报名的商家大部分是活跃度高的;此时如果分析运营策略对商家的影响并且直接比较“报名商家”和“无报名商家”在活动开始后的营收,会导致运营策略收益被高估。匹配的逻辑是找出和有报名的商家在某些特征上最相似的未报名商家,并且进行有针对性的比较:

基于上述场景举一个简单分析案例,假设商家报名活动数据如下:
| 商家ID | 是否报名活动(T) | 报名前7日是否登陆抖店(X) | 报名后7日GMV,元(y) |
|---|---|---|---|
| 1 | 1 | 0 | 10 |
| 2 | 0 | 0 | 11 |
| 3 | 1 | 1 | 3 |
| ... | ... | ... | ... |
定义因变量y为“商家报名后7日GMV”,特征变量X为“报名前7日是否登陆抖店”,实验变量T为“是否报名活动”。基于上述数据,如果直接用线性回归模型 $y=\alpha T+\varepsilon$ 求解实验效应 $\alpha$,策略效应会包含活跃度高的商家以及活跃度低的商家之间的“自选择偏差”。因此我们需要用匹配的方法,为报名了活动的商家1和商家3在未报名活动的商家中寻找相似商家 - 商家1需要在“报名前7日无登陆抖店”的商家中搜寻对照组、商家3需要在“报名前7日有登陆抖店”的商家中搜寻对照组。
架构
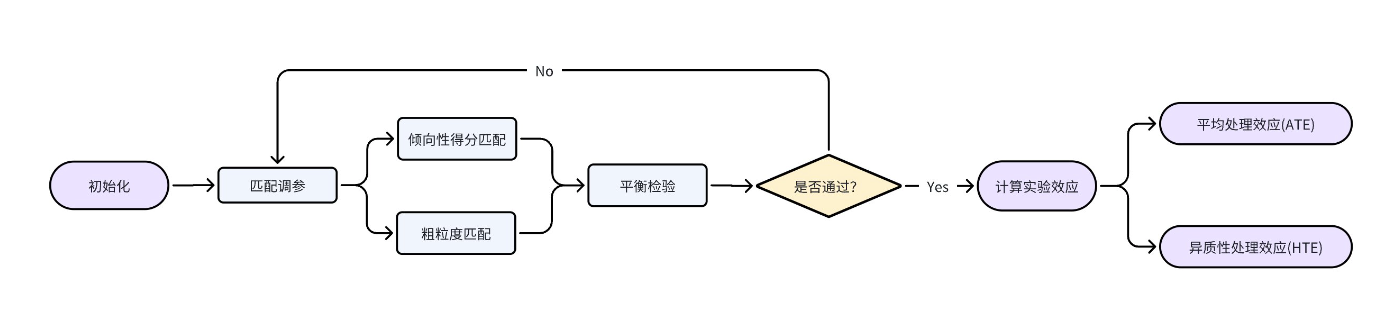
CausalMatch 包括如下组件:
1. 初始化:包括预处理数据等功能。
2. 匹配调参:包括有参的倾向性得分匹配(Propensity Score Matching)以及非参的粗粒度匹配(Coarsened Exact Matching)两种方法。
3. 平衡检验:对匹配前和匹配后输出特征变量的均值差异检验。
4. 计算实验效应:包括平均处理效应(ATE)和异质性处理效应(HTE)两种估计方法。
使用指南
基于前述电商场景下的案例,我们在这里展示如何使用CausalMatch对样本进行纠偏并估计纠偏后的策略效应。首先在shell中安装指令如下:
pip install causalmatch==0.0.2
安装后,可以在jupyter notebook中运行如下代码:
from causalmatch import matching
id = '商家ID'
X = ['报名前7日是否登陆抖店']
y = ['报名后7日GMV,元']
T = '是否报名活动'
# 1.初始化函数,包括清洗数据等功能;df为包含上述变量的pandas dataframe
match_obj = matching(data = df, T = T, X = X, y = y, id = id)
# 2.PSM匹配
match_obj . psm(n_neighbors = 1, model = LogisticRegression(C=1e6), trim_percentage = 0,caliper = 1, test_size = 0.2)
# 3.平衡检验
print(match_obj . balance_check(include_discrete = True))
# 4.计算平均处理效应ATE
print(match_obj . ate())
我们提供有参的倾向性得分匹配(Propensity Score Matching)以及非参的粗粒度匹配(Coarsened Exact Matching)两种估计方法用于筛选策略分析样本,并且提供平均处理效应(ATE)和异质性处理效应(HTE)两种估计方法用于计算策略效果(具体细节请参考github的README介绍)。
03 项目特点
灵活配置
CausalMatch 支持用户灵活接入 scikit-learn 函数输入,可自由调参优化倾向性得分模型,以实现更高的可扩展性和弹性。
构建完整分析流程
在 CausalMatch 的架构中允许用户以最少代码成本构建规范的分析流程,帮助减少因果分析本身由于不确定性带来的业务问题。
04 总结
CausalMatch v0.0.1 反映了开发人员在过去半年中取得的成就,感谢所有参与此版本的贡献者。我们非常期待更多开发者和用户能加入到 CausalMatch 开源社区中,和我们一起交流和探讨数据科学相关话题。如果有问题,请随时在github issue中向我们反馈。同时,团队积极关注社区技术动向,拥抱开源和标准,欢迎更多同学加入我们,一起交流学习。点击链接(https://job.toutiao.com/s/ih8wxpwx)了解职位详情,欢迎大家投递简历至shenheng.shen@bytedance.com。



















































