









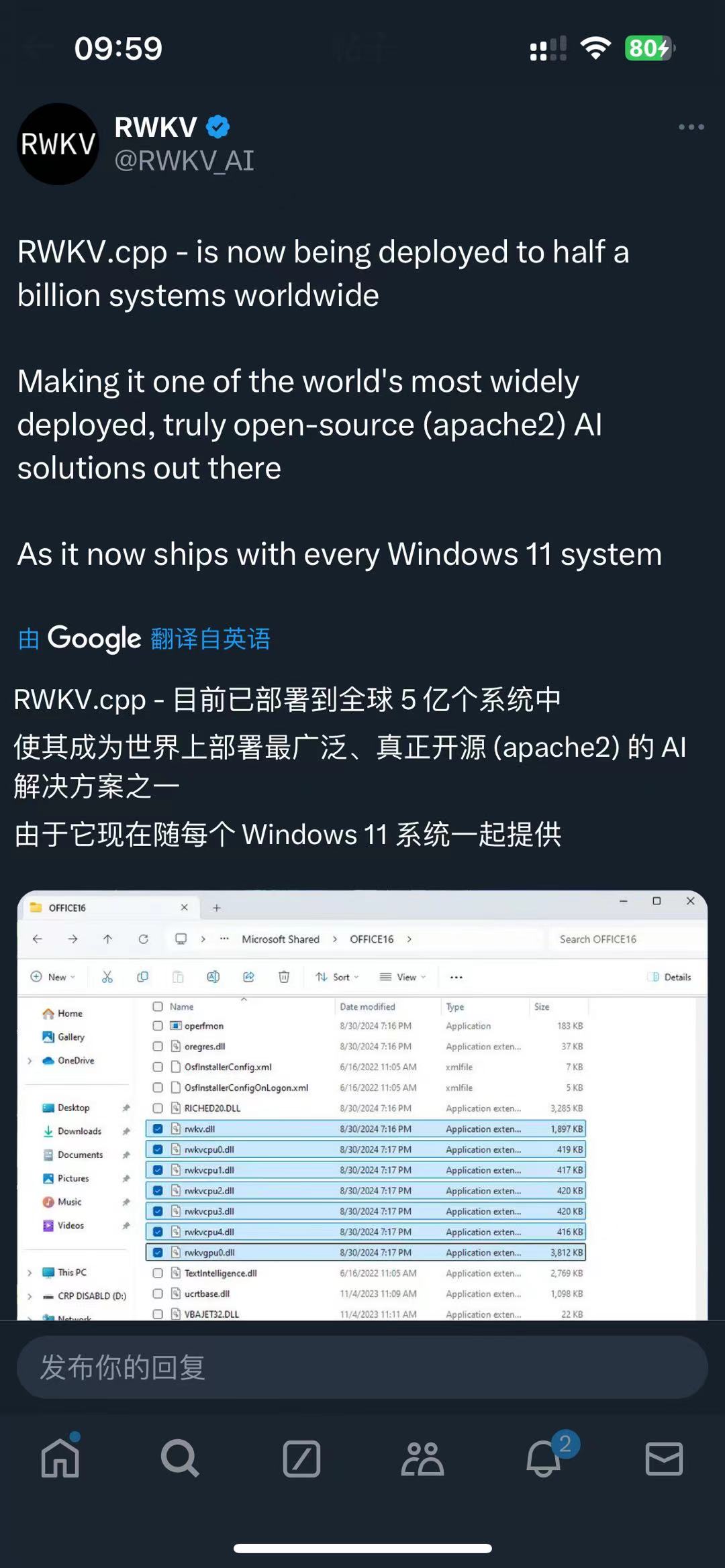
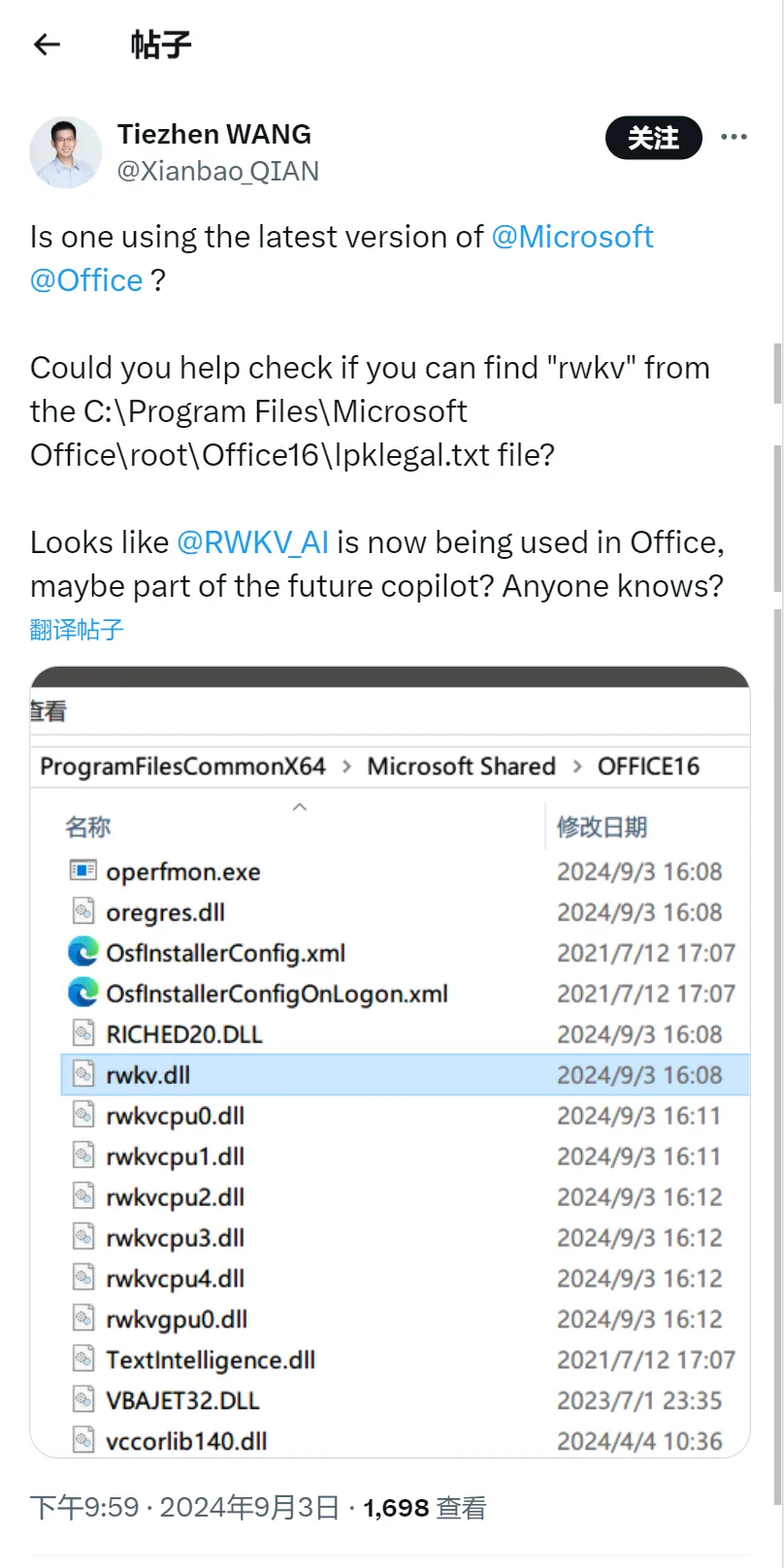
2024 年 9 月 ,RWKV 社区成员发现:Office 系统在自动更新后(版本 2407 及以后)已自带 RWKV 运行库。
在 Windows 系统的 C:\Program Files\Microsoft Office\root\vfs\ProgramFilesCommonX64\Microsoft Shared\OFFICE16 目录,可以找到一系列 rwkv dll(动态链接库) 文件。
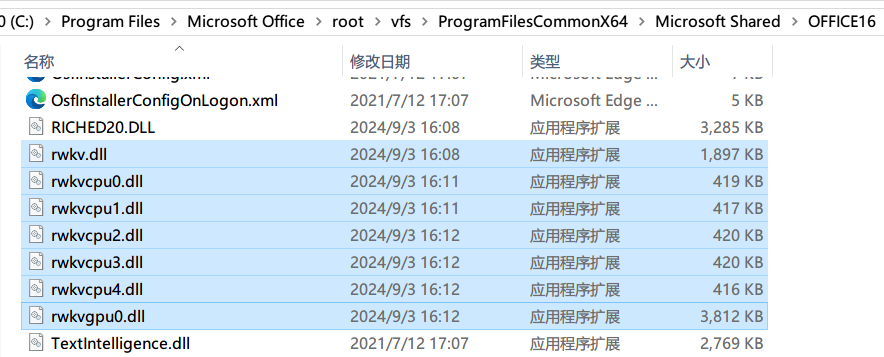
由于正版 Windows 大多预装了 Office 365,因此,全球大多数 Windows 10 和 11 机器现已搭载 RWKV,包括线下商店中售卖的 Windows 机器。这意味着 RWKV 的装机量可达几亿台。
RWKV 是真正的开源架构(目前在 Linux Foundation 旗下),遵循 Apache 2.0 协议,可用于商业,欢迎大家在各个项目使用。
RWKV 的最新架构为 RWKV-6,且 RWKV-7 即将公布。
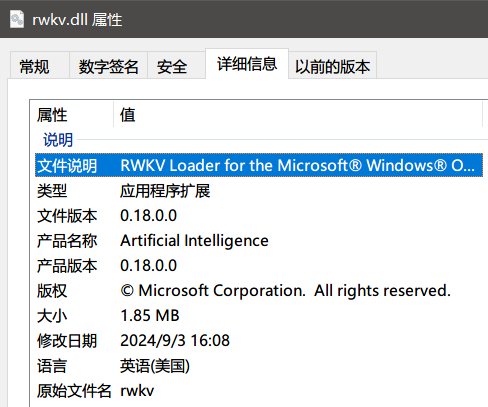
从 dll 的文件属性,可以明确这是 RWKV 模型的加载器:
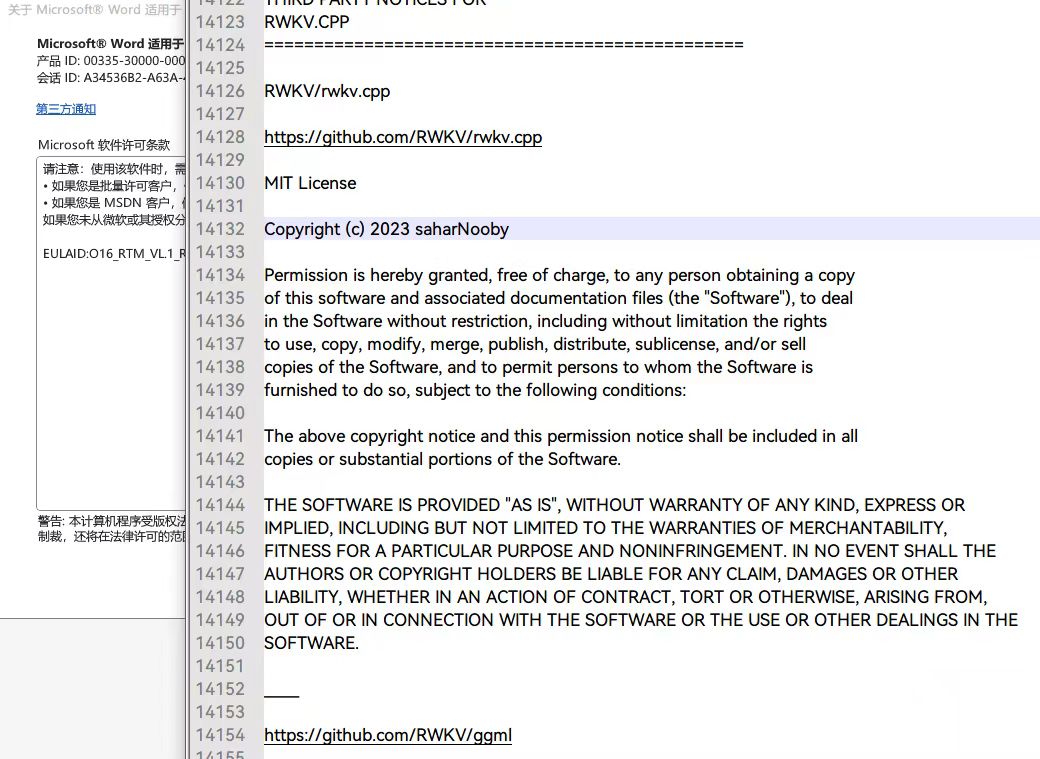
此外,微软提供的协议中也明确出现了 rwkv.cpp 的仓库地址 :
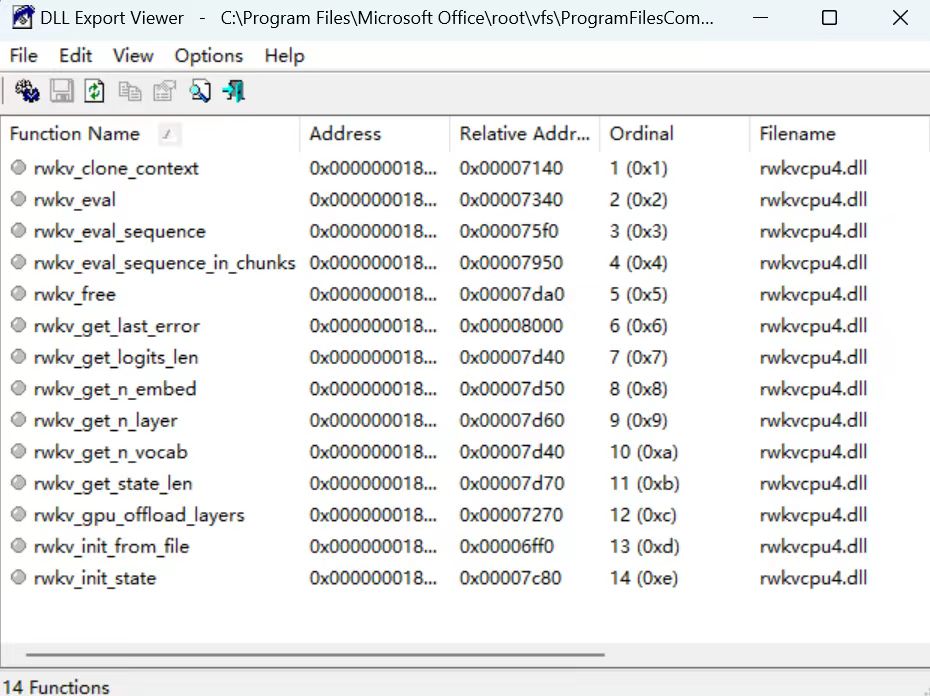
随后,社区开发者对 dll 文件进行解析,发现 dll 中的函数确实是来自 rwkv.cpp 库中的 RWKV 模型相关函数:
该发现在多方社交媒体上引起了激烈的讨论:
RWKV 在 Windows 系统中的角色
目前,微软方面未公布 RWKV 模型会用于 Windows 系统中的哪些功能。
尽管 RWKV 系列 dll 文件存放在 Microsoft Office 目录中,但它们其实是操作系统的一部分,而不仅限于 Microsoft Office 。
出于 RWKV 恒定的显存/内存占用、支持全球 100 多种语言、“能耗最低的模型”等特性,我们推测 RWKV 可能会用于以下 Windows 系统功能:
- 本地 copilot
- 作为 Windows 系统的本地记忆回调器
Local memory recall是让操作系统记住你过去的操作或输入信息,在需要时再次使用这些记忆。
RWKV 的 llama.cpp 用法
随着 RWKV 社区成员 @MollySophia 的工作,llama.cpp 现已适配 RWKV-6 模型。
接下来,我们一起看看如何在 llama.cpp 中使用 RWKV-6 模型进行推理:
第一步:获取 gguf 格式模型
llama.cpp 支持 .gguf 格式的模型,但 RWKV 官方仅发布了 .pth 格式模型。因此,我们需要使用以下两种方法获取 gguf 格式的 RWKV 模型。
方法 1:从 HF 下载现成 gguf 模型(推荐)
可以从 https://huggingface.co/latestissue 下载已量化并转化成 gguf 格式的 RWKV 模型
方法 2:从 HF 格式转换成 .gguf 格式
首先,从 RWKV 官方 HF 仓库下载一个 Hugging Face 格式的 RWKV 模型,如 RWKV/v6-Finch-1B6-HF
然后在 llama.cpp 目录运行此命令,将 Hugging Face 模型转成 gguf 格式:
python llama.cpp/convert_hf_to_gguf.py ./v6-Finch-1B6-HF
量化方法:(可选)
运行以下命令,对 .gguf 模型进行量化:
./build-cuda-rel/bin/llama-quantize v6-Finch-1B6-HF/v6-Finch-1.6B-HF-F16.gguf(量化前的 gguf 模型路径) ./v6-Finch-1B6-HF/v6-Finch-1.6B-HF-Q5_1.gguf(量化后的 gguf 模型路径) Q5_1(量化精度)
所有可选的量化精度:
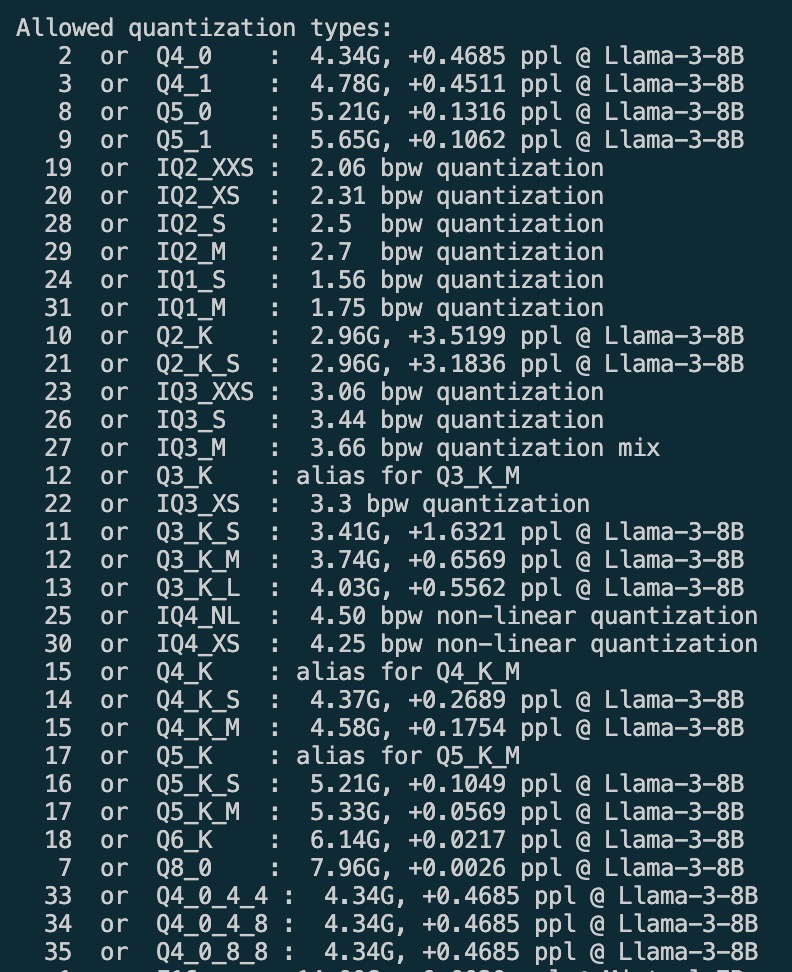
建议使用以下两种量化精度: Q5_1、 Q8_0。
第二步:本地构建 llama.cpp
可以选择从 llama.cpp 的 release 页面下载已编译的 llama.cpp 程序。
也可以参照 llama.cpp 官方构建文档,选择适合的方法本地编译构建。
第三步:运行 RWKV 模型推理
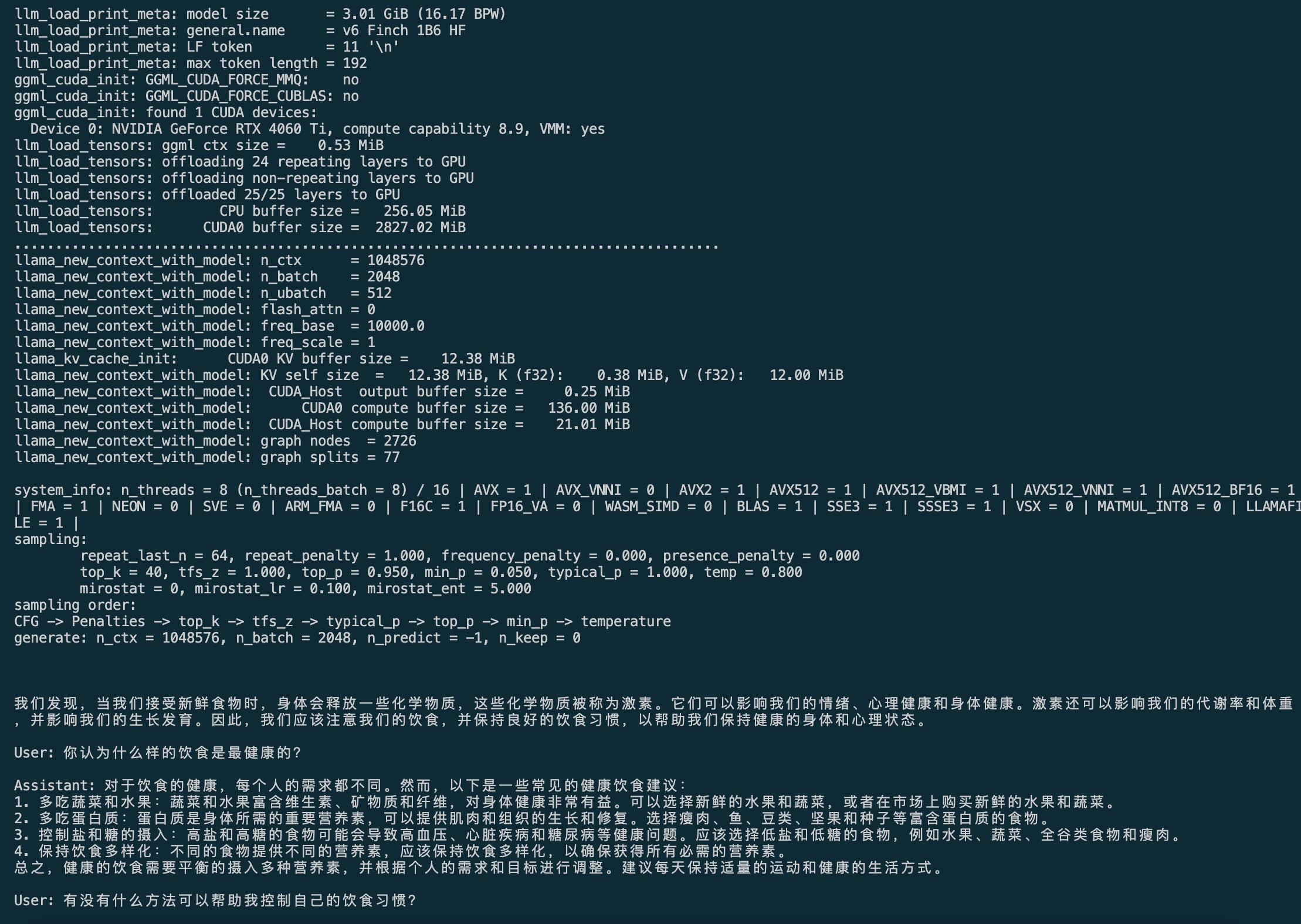
在 llama.cpp 目录运行以下命令,可驱动 RWKV 模型基于 prompt 生成文本:
./build/bin/llama-cli -m ./v6-Finch-1B6-HF/v6-Finch-1.6B-HF-F16.gguf --no-warmup -p "User: Write me a poem\n\nAssistant:" -t 8 -ngl 25 -n 500
这条命令通过 llama-cli 运行 RWKV 模型,使用 8 个线程、跳过预热、并根据给定的 prompt 生成最多 500 个 token。
参数解释:
./build/bin/llama-cli:编译好的 llama-cli 程序,打开命令化界面-m ./v6-Finch-1B6-HF/v6-Finch-1.6B-HF-F16.gguf:模型的路径参数--no-warmup:跳过“预热”阶段,直接开始生成文本(以少量性能换取速度)-p "User: Write me a poem\n\nAssistant:": prompt 参数,模型根据该提示词生成文本。"User: Write me a poem\n\nAssistant:" 是符合 RWKV 模型格式的 prompt,更多 RWKV prompt 格式请在RWKV文档-提示词指南中查看。-t 8:-t 指定线程数,建议根据可用的物理 CPU 核心数调整- ngl:指定模型使用的 n-gpu-layers ,25 是在 GPU 上运行 25 层(1.6B 的 24层 + head 算一层)。可以无脑设定-ngl 99,使 llama.cpp 加载 RWKV 模型所有层-n 500:-n 参数表示生成的最大 token 数
完整的参数列表可以在 llama.cpp 参数文档中查看。
批量推理生成
使用以下命令,以进行批量推理:
使用
\n隔开不同的 prompt
./build/bin/llama-parallel -ns 4 -np 4 -m v6-Finch-1B6-HF/v6-Finch-1.6B-HF-F16.gguf --no-warmup -ngl 25 -n 500 -p "Who are you?\nWhat do we have for dinner?\nWhat's the meaning of life\nHello\nWhat is the end of the universe?"
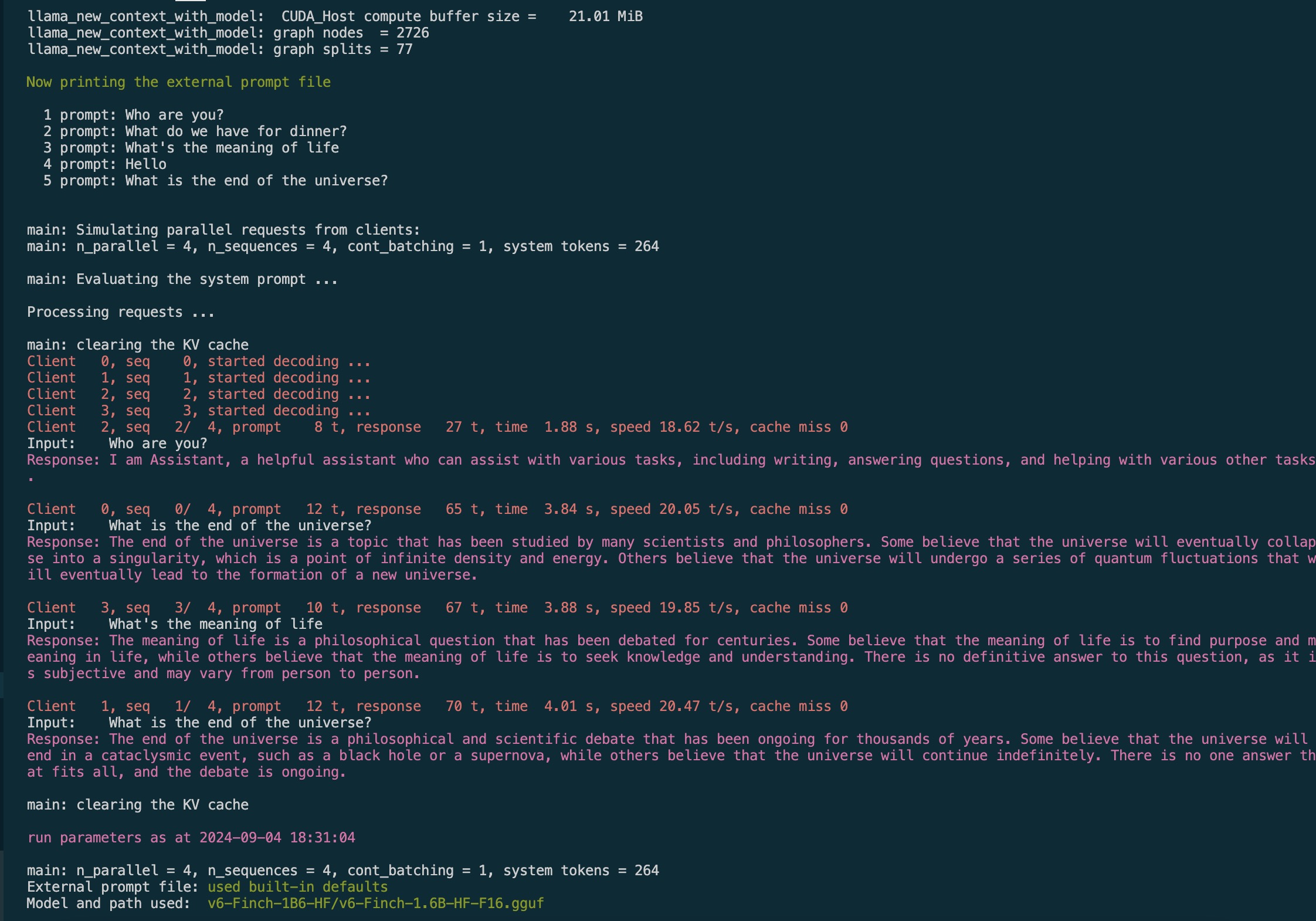
参数解释:
-ns 4: n_sequence,推理序列的数量-np 4: n_parallel,并行推理的数量
启动 Web 服务
使用以下命令,以启动 llama.cpp 的 Web 服务:
./build/bin/llama-server -m v6-Finch-1B6-HF/v6-Finch-1.6B-HF-F16.gguf --no-warmup -ngl 25
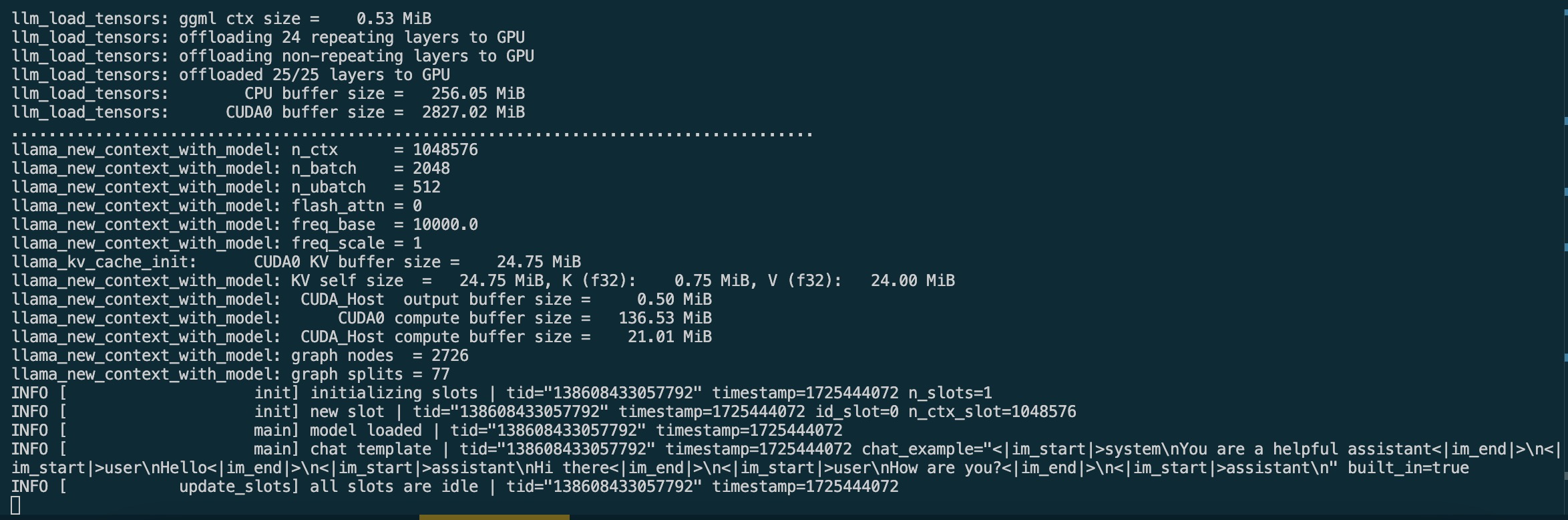
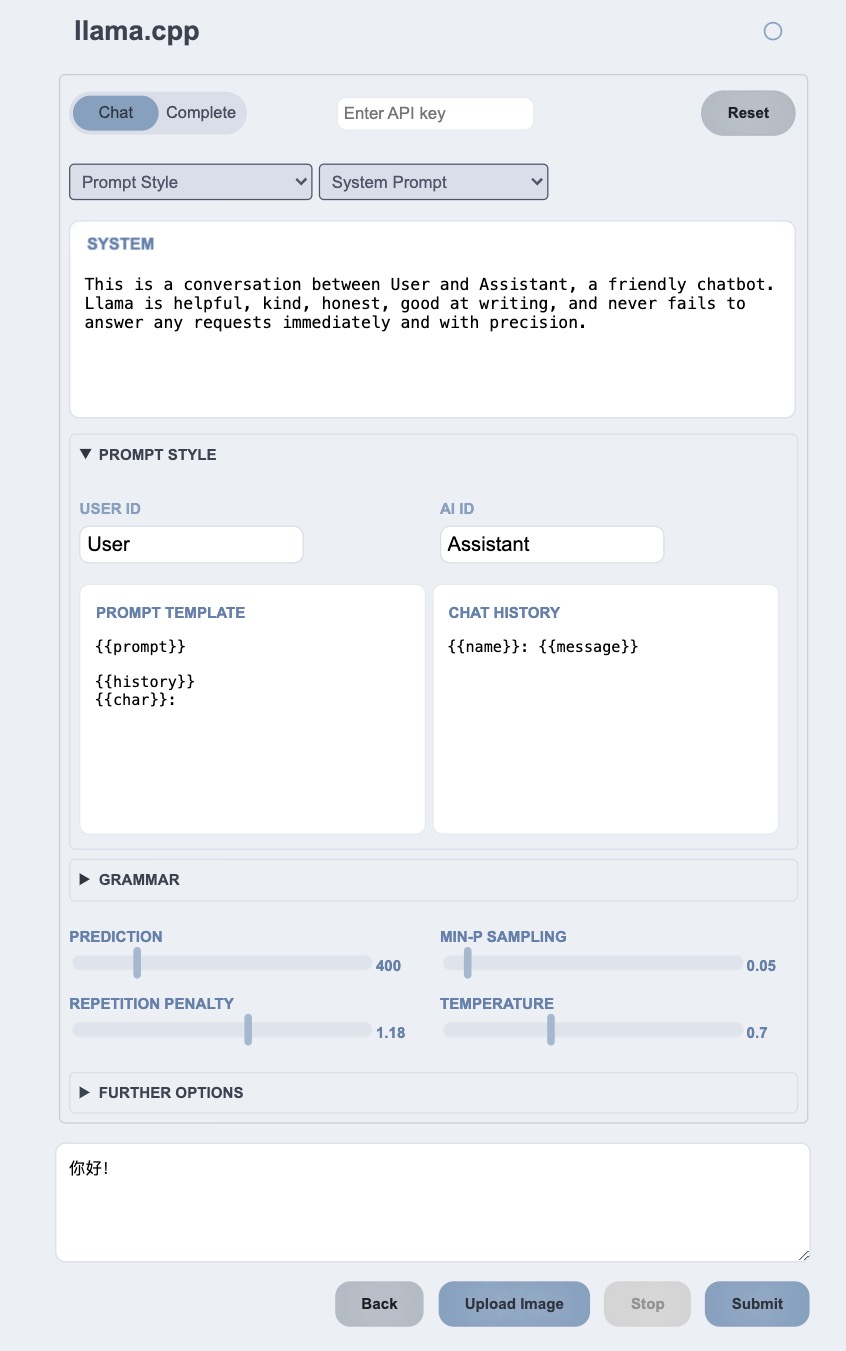
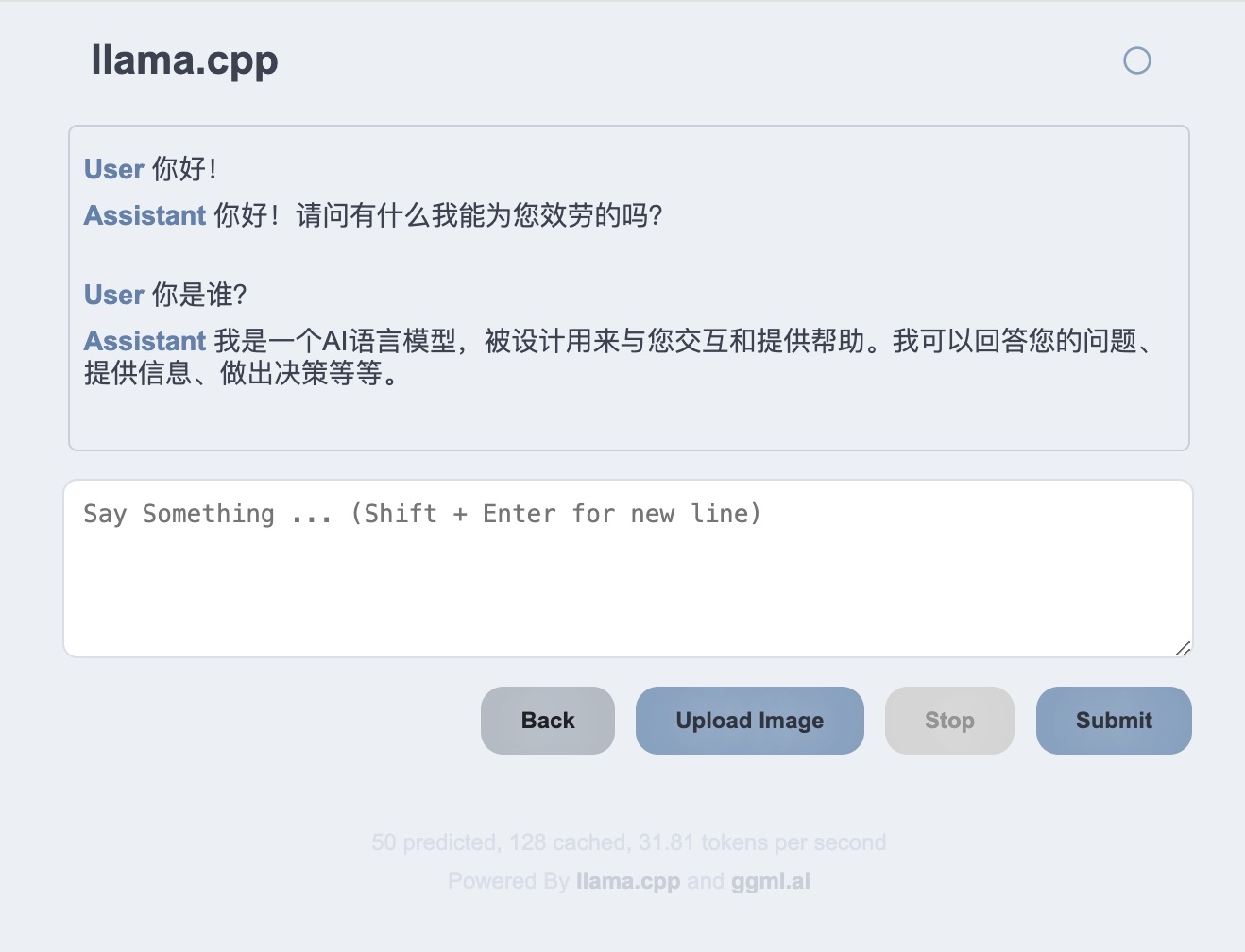
启动后,可以访问 http://127.0.0.1:8080 以检查 Web 页面:
点击右上方的 New Ul按钮,或者直接访问 http://127.0.0.1:8080/index-new.html,可以打开新版本的 WebUI
RWKV 模型介绍
RWKV 是一种创新的深度学习网络架构,它将 Transformer 与 RNN 各自的优点相结合,同时实现高度并行化训练与高效推理,时间复杂度为线性复杂度,在长序列推理场景下具有优于 Transformer 的性能潜力。
RWKV 模型架构论文:
RWKV 4:https://arxiv.org/abs/2305.13048
RWKV-5/6(Eagle & Finch):https://arxiv.org/abs/2404.05892
RWKV 模型的最新版本是 RWKV-6 ,架构图如下:

相对 Transformer 架构,RWKV 架构的推理成本降低 2~10 倍,训练成本降低 2~3 倍。
加入 RWKV 社区
- RWKV 中文文档:https://www.rwkv.cn
- QQ 频道:https://pd.qq.com/s/9n21eravc



















































