









原文作者:Amir Rawdat - F5 解决方案工程师转载来源: NGINX 中文官网
NGINX 唯一中文官方社区 ,尽在 nginx.org.cn 阅读原文。
业内许多性能基准测试,都是基于峰值吞吐量或每秒请求数 (RPS),但这些指标可能会过分简化实际站点的性能情况。以峰值吞吐量或接近峰值吞吐量运行其服务的企业寥寥无几,因为无论采用哪种方式,10% 的性能变化都会产生重大影响。站点所需的吞吐量或 RPS 不是无限的,而是取决于外部因素,例如站点必须服务的并发用户数量和每个用户的活跃程度。最终重要的是您的用户能够获得最佳服务。最终用户并不在乎有多少人正在访问您的站点。他们只在意自己所获得的服务,而且他们无法接受因系统过载而导致的性能低下。
因此,对于企业真正重要的是,即使在高负载下也要能为所有用户提供持续的低延迟的可靠性能。在对比作为反向代理运行于 Amazon Elastic Compute Cloud (EC2) 之上的 NGINX 和 HAProxy 时,我们从以下两方面着手探讨:
-
测量这两种代理可以可靠处理的负载水平
-
计算延迟指标百分位数的分布情况,这是与用户体验最直接相关的指标
测试程序和收集的指标
我们使用压测工具 wrk2 模拟了一个客户端,在规定的时间段内发出连续的 HTTPS 请求。被测系统(HAProxy 或 NGINX)充当反向代理,与 wrk 线程模拟的客户端建立加密连接,将请求转发到运行 NGINX Plus R22 的后端 Web 服务器,Web 服务器将生成的响应(一个文件)返回给客户端。
这三个组件(客户端、反向代理和 Web 服务器)都在Ubuntu 20.04.1 LTS, EC2 的 c5n.2xlarge Amazon Machine Image (AMI) 实例上运行。
如上所述,我们从每次测试运行中收集了完整的延迟指标百分位分布。延迟指标是指客户端从生成请求到接收响应所用的时间。延迟百分位分布会将测试期间收集的延迟测量值从高到低(即从延迟时间最长到最短)进行排序。
测试方法
客户端
taskset -c 0-3 wrk -t 4 -c 100 -d 30s -R requests_per_second --latency https://adc.domain.com:443/为了模拟多个客户端访问 Web 应用,我们生成了 4 个 wrk 线程,这些线程共与反向代理建立 100 个连接。在 30 秒的测试运行期间,该脚本生成了指定数量的 RPS。这些参数对应于以下 wrk2 选项:
-
‑t 选项 – 要创建的线程数 (4)
-
‑c 选项 – 要创建的 TCP 连接数 (100)
-
‑d 选项 – 测试期间的秒数(30 秒)
-
‑R 选项 – 客户端发出的 RPS 数量
-
‑‑latency 选项 – 输出结果包含校正的延迟百分位信息
我们在一组测试中逐渐增加了 RPS 的数量,直到其中一个代理的 CPU 利用率达到 100%。更多信息请参阅下文“性能测试结果”一节。
客户端和代理之间的所有连接均通过采用 TLSv1.3 的 HTTPS 建立。我们使用 256 位 ECC 密钥加密、PFS (Perfect Forward Secrecy,完全向前保密) 和 TLS_AES_256_GCM_SHA384 密码套件。(鉴于 TLSv1.2 仍被广泛使用,因此我们使用 TLSv1.2 重新运行了测试;结果与 TLSv1.3 非常相似,所以此处不再赘述。)
HAProxy:配置和版本控制
-
必须为每个进程单独定义配置参数(包括限制、统计数据和速率)。
-
性能指标将按进程收集;整合这些指标需要额外的配置,而相关配置可能会非常复杂。
-
每个进程单独处理健康状况检查,因此目标服务器会被按进程(而非预想中的按服务器)进行探测。
-
会话持久化无法实现。
由于上述问题,HAProxy 官方也强烈建议不要使用其多进程实现。下面引述摘自 HAProxy 配置手册:
使用多进程很难进行调试,强烈建议不要使用。
HAProxy 在 1.8 版中引入了多线程作为多进程的替代方案。多线程主要解决了状态共享问题,但正如我们在下文“性能测试结果”一节中所述,在多线程模式下的 HAProxy 的性能又不如多进程的模式下的性能。
我们的 HAProxy 配置包含了多线程模式 (HAProxy MT) 和多进程模式 (HAProxy MP) 的配置。为了在测试过程中在每个 RPS 级别上交替使用两种模式,针对相应的代码行,我们通过适当修改注释,以及重启 HAProxy 以使不同的配置生效:
$ sudo service haproxy restart以下是提供 HAProxy MT 的配置:在一个进程下创建了四个线程,并且每个线程绑定一个CPU核。HAProxy MP(下面注释的部分)中有四个进程,并且每个进程都固定在绑定到到一个 CPU 核上。
global
#Multi-thread mode
nbproc 1
nbthread 4
cpu-map auto:1/1-4 0-3
#Multi-process mode
#nbproc 4
#cpu-map 1 0
#cpu-map 2 1
#cpu-map 3 2
#cpu-map 4 3
ssl-server-verify none
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
maxconn 4096
defaults
log global
option httplog
option http-keep-alive
frontend Local_Server
bind 172.31.12.25:80
bind 172.31.12.25:443 ssl crt /etc/ssl/certs/bundle-hapee.pem
redirect scheme https code 301 if !{ ssl_fc }
default_backend Web-Pool
http-request set-header Connection keep-alive
backend Web-Pool
mode http
server server1 backend.workload.1:80 check
NGINX:配置和版本控制
user nginx;
worker_processes auto;
worker_cpu_affinity auto 1111;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
keepalive_timeout 65;
keepalive_requests 100000;
server {
listen 443 ssl reuseport;
ssl_certificate /etc/ssl/certs/hapee.pem;
ssl_certificate_key /etc/ssl/private/hapee.key;
ssl_protocols TLSv1.3;
location / {
proxy_set_header Connection ' ';
proxy_http_version 1.1;
proxy_pass http://backend;
}
}
upstream backend {
server backend.workload.1:80;
keepalive 100;
}
}
性能测试结果
由于反向代理充当应用的前端,因此其性能至关重要。
我们逐渐增加 RPS 的量级来测试每个反向代理(NGINX、HAProxy MP 和 HAProxy MT),直到其中一个的 CPU 利用率达到 100%。在 CPU 未耗尽的 RPS 能力上,这三个反向代理的性能不相上下。
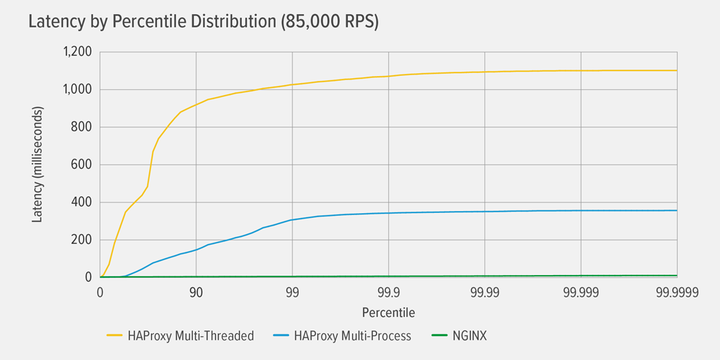
RPS 85,000级别上,在第 90 个百分位数上,HAProxy MT 的延迟指标骤升直,在逐渐提升到大约 1100 毫秒 (ms) 时逐渐趋于平稳。
较之 HAProxy MT,HAProxy MP 的性能更好 —— 其延迟在第 99 个百分位前一直以较慢的速度上升,之后在达到大约 400 毫秒时开始趋于平稳。(以上观察结果证明了 HAProxy MP 更为高效:HAProxy MT 在每个 RPS 级别上使用的 CPU 略多于 HAProxy MP。)
NGINX 在任何百分位上几乎都没有延迟。几乎所有用户访问可能出现的最高延迟(在第 99.9999 个百分位)大约为 8 毫秒。
关于用户体验,这些结果说明了什么呢?正如引言所述,从最终用户的角度来看,真正重要的指标是响应时间,而非被测系统的服务时间。
人们普遍存在一种误解,认为延迟分布中的中位数最能代表用户体验。事实上,中位数是大约一半的响应都要体验到的更高的延时!用户通常会在每次页面加载时发出许多请求并访问许多资源,因此他们的一些请求必然会在图表的上百分位(第 99 到第 99.9999 个百分位)处出现延迟。用户无法忍受性能低下,而高百分位的延时指标恰恰代表了多数请求都会经历的延时,因此更容易被他们注意到。
举个例子:您在杂货店结账的体验取决于从您排队结账的那一刻到离开商店所用的时间,而不仅仅是收银员进行商品扫码结算所花费的时间。例如,如果您前面的一位顾客对某件商品的价格提出质疑,而收银员必须找人进行核实,那么您的整体结账时间就会比平时长得多。
为了将这一点计入延迟结果,我们需要纠正所谓的 coordinated omission,其中(如 wrk2 README 文件末尾的注释中所述)“高延迟响应会触发负载生成器与服务器进行协调,从而避免在高延迟期间进行测量”。幸运的是,wrk2 默认纠正了 coordinated omission(有关 coordinated omission 的更多详细信息,请参阅 README 文件)。
当在 85,000 RPS 下 Haproxy MT 耗尽 CPU 时,许多请求都会出现高延迟。这些情况理应纳入数据,因为我们正在调整 coordinated omission。只要一两个高延迟请求便会延迟页面加载,让人感觉性能欠佳。假设一个真实系统一次为多位用户提供服务,即使只有 1% 的请求出现高延迟(第 99 个百分位的值),大部分用户都可能会受到影响。
结语
性能基准测试的要点之一是确定应用是否具有足够的响应能力来满足用户需求并留住用户。
NGINX 和 HAProxy 均基于纯软且采用事件驱动型架构。尽管 HAProxy MP 的性能优于 HAProxy MT,但由于无法在各个进程之间共享状态,因此管理变得更加复杂,详见上文 HAProxy:配置和版本控制一节。HAProxy MT 消除了这些局限性,但却降低了性能,如上述结果所示。
借助 NGINX,您则无需做出取舍 —— 因为进程之间共享状态,所以无需采用多线程模式。您可以获得多进程的卓越性能,而不会遇到 HAProxy 中的限制 —— 毕竟,这种限制是如此严重,以至于 HAProxy 直接建议不要使用其多进程实现。






















































