









随着业务的蓬勃发展,各企业对数据处理的灵活性和可扩展性提出了更高的要求。在此背景下,JSON、XML 等半结构化数据凭借其较强的灵活性在众多企业得到广泛应用。然而,传统关系型数据库结构严格,难以应对半结构化数据的复杂性及多样性。为有效存储及分析这些数据,Apache Doris 针对不同应用场景提供了 Array、Map、Struct、JSON、VARIANT半结构化数据存储分析解决方案。
本文我们将聚焦企业最普遍使用的 JSON 数据,分别介绍业界传统方案以及 Apache Doris 半结构化数据存储分析的三种方案,并通过图表直观展示这些方案的优势与不足。同时,结合具体应用场景,分享不同需求场景下的使用方式,帮助用户快速选择最合适的 JSON 数据存储及分析方案。
半结构化数据特点及挑战
业界通常将数据分为结构化数据、非结构化数据、半结构化数据这三大类型:
- 结构化数据:关系型数据库是一种典型的结构化数据存储方式,其核心特点是结构严格且固定。例如,一个包含五列数据的表,其数据类型可能是字符串(string)、整数(int)或日期(date)等。字段名和类型均是预先设定、不可轻易改变,具备读写性能出色的优势。
- 非结构化数据:非结构化数据指没有固定结构的数据,例如文本、音频和视频等,这类数据缺乏明显的结构特征。例如,进行文本检索时,需要查找特定的关键字或短语。(Apache Doris 从 2.0 版本开始,提供了倒排索引等功能,可以实现对非结构化文本数据的高效检索,包括关键词检索、短语检索等。)
- 半结构化数据: 半结构化数据虽然拥有一定的结构,但不严格固定,具有很强的灵活性。比较典型的是 JSON 格式,可以便捷地增加新字段或删除不需要的字段,以适应数据交互和存储的需求。
Github 用户操作记录日志 GH Archive 是典型的半结构化 JSON 数据,通过下方示例 CreateEvent 和 PushEvent ,展示真实的数据。
-
CreateEvent
{ "id": "37066529202", "type": "CreateEvent", "actor": { "id": 151583193, "login": "BlankTMing", "display_login": "BlankTMing", "gravatar_id": "", "url": "https://api.github.com/users/BlankTMing", "avatar_url": "https://avatars.githubusercontent.com/u/151583193?" }, "repo": { "id": 780596894, "name": "BlankTMing/ManifestAutoUpdate-", "url": "https://api.github.com/repos/BlankTMing/ManifestAutoUpdate-" }, "payload": { "ref": "2715611_469785097560218038", "ref_type": "tag", "master_branch": "main", "description": null, "pusher_type": "user" }, "public": true, "created_at": "2024-04-01T23:00:00Z" } -
PushEvent
{ "id": "37066529220", "type": "PushEvent", "actor": { "id": 73488070, "login": "hafsa1319", "display_login": "hafsa1319", "gravatar_id": "", "url": "https://api.github.com/users/hafsa1319", "avatar_url": "https://avatars.githubusercontent.com/u/73488070?" }, "repo": { "id": 746560097, "name": "hafsa1319/akademi_report", "url": "https://api.github.com/repos/hafsa1319/akademi_report" }, "payload": { "repository_id": 746560097, "push_id": 17799451996, "size": 1, "distinct_size": 1, "ref": "refs/heads/main", "head": "fc7a15d71539a3588f43e41f9034bfb4b4464358", "before": "e29be382e67485ff5a8a88264f9b3272b2366c3a", "commits": [ { "sha": "fc7a15d71539a3588f43e41f9034bfb4b4464358", "author": { "email": "73488070+hafsa1319@users.noreply.github.com", "name": "hafsa1319" }, "message": "Add or update home/hafsa-report/htdocs/report.hafsa.de/akademi/csv/telcHS2402.csv", "distinct": true, "url": "https://api.github.com/repos/hafsa1319/akademi_report/commits/fc7a15d71539a3588f43e41f9034bfb4b4464358" } ] }, "public": true, "created_at": "2024-04-01T23:00:00Z" }
参考 Wikipedia 上的定义,结合实际业务落地的经验,半结构化数据具有以下特点:

-
不严格遵循结构化表模型:半结构化数据不严格遵循关系数据库中的表格结构,通常包含标签(tags)或其他形式的标记,以表明其语义或字段名。以上方 GH Archive 示例,"id", "type", "payload" 是标签或者字段名。
-
自描述结构但不固定: 半结构化数据具有一定自描述性,一般通过键值对(Key-Value Pairs)描述内部结构。这种结构并不固定,可能包含不同数量的字段或类型。以上方 Github Event 示例,PushEvent 的
payload字段就比 CreateEvent 多了ref head commits 等字段。 -
通常有嵌套结构: 嵌套结构的复杂性较高,表现为一个结构体内部嵌套另一个结构体,甚至结构体或数组中再嵌套其他结构体或数组,形成多层次、复杂的数据结构。以上方 GH Archive 示例,CreateEvent 中
actor repo payload有简单的嵌套子字段,而 PushEvent 的 payload 中commits字段则出现了数组嵌套结构体、结构体再嵌套结构体的复杂结构。
上述特点为半结构化数据的存储和分析带来很大的挑战,也是业界数据库要解决的主要问题:
-
如何支持灵活的 Schema:半结构化数据具备较高的灵活性,字段随着业务发展而增加/减少,类型也可能变化,数据中的嵌套结构也让字段变的更加复杂,因此要求数据库能够支持灵活的 Schema。
-
如何高效存储:半结构化数据中包含大量重复的自描述内容,比如大量重复的字段名,通常是由机器产生。如果按原始数据存储,数据冗余存储带来的资源浪费非常高,因此要求数据库能够高效存储。
-
如何极速分析:半结构化数据通常为文本形式,直接对文本解析和分析虽然可行但性能较差。特别是在分组、聚合、过滤等操作时,要从大量的字段中分析其中的几个字段,将带来很多不必要的 IO 和解析开销。
接下来,我们就以 JSON 数据为例,了解业界为应对这些挑战的常见解决方案。
传统解决方案
01 通过 ETL 转为结构化数据
方案一是在 ETL 过程将半结构化数据转化为结构化数据,主要借助 ETL 工具 / 数据库导入过程中实现。比如在 Doris 中,可以借助导入的 JSON 字段映射功能,将数据映射到预设的表结构中。
该方案的优势是:转化为结构化形式后,可充分利用结构化数据处理的优势,提供较高的存储压缩率和出色的分析性能。
该方案的问题是:当上游数据源字段发生变化(如增加或删除字段)时,下游表结构也进行相应修改。如不修改表结构,新增的数据将无法完整写入。而修改过程非常繁琐,通常需要多个团队协作与配合,处理起来并不高效,且这种方式也丧失了半结构化数据的灵活性。
02 String 存储和 JSON 函数分析
方案二是将 JSON 数据转存到 String 字段中,String 支持存储任意文本数据,可解决 Schema 灵活性差的问题。当需要对这些 JSON 数据查询分析时,可使用专门的 JSON 函数提取所需字段,如可通过json_extract、json_extract_int、json_extract_double等函数解析并提取特定字段值。
该方案的问题是:每次查询都需要使用 JSON 函数解析和遍历整行 JSON 文本,效率低、分析性能差。此外,由于 JSON 文本以行为单位进行存储,其压缩效率不如列式存储高。
03 Elasticsearch Dynamic Mapping
方案三为 Elasticsearch 的 Dynamic Mapping ,该方案可自动识别新增 JSON 数据的字段名和类型,并将字段动态添加到 Elasticsearch Index Mapping (类似 Table Schema) 中。
该方案的问题是:
-
字段类型一旦确定不可更改,若字段首次被写入为整型(int),后续则必须保持为整型;如果尝试写入非整型数据(如浮点型 float 或者字符串类型 string),Elasticsearch 将拒绝写入并可能丢弃这条数据,限制了数据类型随业务发展而演变的灵活性。
-
当写入数据包含大量字段时,Elasticsearch Mapping 会迅速膨胀,这是因为 Elasticsearch 会将每个字段展开,字段多的时候(比如超过 500)元数据压力增大,严重影响查询,而且 Mapping 只增不减,即便删除字段多的行也不能减少元数据。
基于 Apache Doris 的半结构化数据存储及分析方案
针对传统方案存在的问题,Apache Doris 结合不同场景下对半结构化数据存储和分析的需求,提供了三种解决方案,用户可以根据实际场景灵活选择。
01 Array Map Struct
Array、 Map 、Struct 数据类型支持嵌套的固定 Schema,常用于用户行为和画像分析、查询数据湖中 Parquet ORC 等格式数据的场景。
Array Map Struct 可以存储复杂结构数据,Array 存储相同类型的数组,Map 存储键值对(Key-Value ),Struct 存储 n 元组,它们之间可以相互嵌套。
- 优势:采用列式存储,可实现较高的压缩率,节省大量存储空间;因嵌套结构的字段和类型是预先定义且相对固定的,在写入和查询时不再需要动态推断数据的 Schema,执行效率较高。
- 不足:虽可以预先定义出复杂的嵌套结构,但是一旦定义后结构不能随着数据变化自适应。
02 JSON
JSON 数据类型支持**嵌套的不固定 Schema,**常用于点查和部分分析场景。
JSON 数据类型是二进制存储类型,具备 JSON String 的灵活性,任意合法的 JSON 数据均可进行存储,分析时通过 JSON 函数来提取对应字段。
- 优势:点查性能好,JSON 采用行存形式进存储,且 JSON 在写入过程中已完成 JSON 的解析,可从二进制中直接读取数据,查询效率至少比 JSON String 快 2 倍。
- 不足:JSON 存储压缩率低于列存,存储成本也相对较高。同时,因在查询时需要先读取整行 JSON 二进制数据、再读取需要分析的字段,读取效率不如行存高效。
03 VARIANT
VARIANT 数据类型支持嵌套的不固定 Schema,常用于 Log、 Trace、 IoT 等分析场景,业界类似的解决方案还有前文所述的 Elasticsearch Dynamic Mapping。
VARIANT 数据类型可以存储任何合法的 JSON,可自动从 JSON 中抽取字段并推断其类型,并将这些字段存储为 VARIANT 列的子列。这种列式存储方式使得 VARIANT 具备很好的分析性能,当进行聚合/过滤/排序等查询时,只需要读取 Variant 子列数据即可,不会产生额外的数据解析开销,查询性能可获得数量级的提升。
相比于 Elasticsearch Dynamic Mapping ,Doris VARIANT 的优势在于:
- 允许写入不同字段类型,数据文件内部使用最小公共类型存储,数据文件之间采用不同类型存储,互不影响。查询时,可以使用最小公共类型或者用户指定的类型查询。
- 可以将出现频次较低的字段合并为二进制 JSON 存储,以此避免字段过多引发子列和文件膨胀的问题,可以兼顾性能和数据结构的灵活性。
在基于 ClickBench 的测试数据集上,VARIANT 有很好的性能表现。
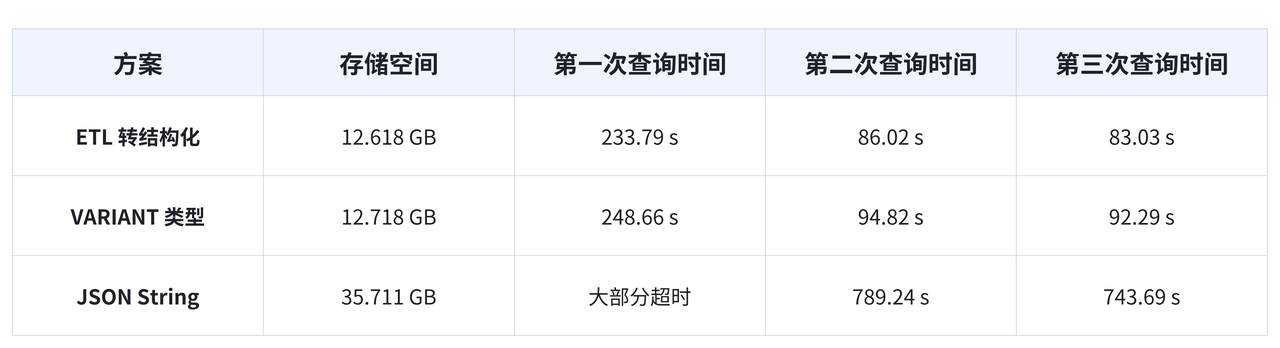
- 在存储方面,其性能与 ETL 转结构化方案相当,均有较低的存储占用;相较于 JSON String,存储资源节省达65%。
- 在查询方面,其性能与 ETL 转结构化方案相当,冷热查询性能差异在 10% 以内;相较于 JSON String 来说,冷查询有 10 倍以上提升、热查询有 8.4 倍的提升,在用户实际的应用场景中,也验证了相似的结果。
方案对比
为直观比较各方案,我们通过图表来展示 ETL 转结构化、JSON String/Binary、Elasticsearch Dynamic Mapping 、Array Map Struct、JSON、VARIANT 等方案的特点,从 Schema 的灵活性、存储效率和分析性能等维度评估各方案的优势和局限性。 (横坐标轴为 Schema 灵活性、纵坐标轴为存储效率 & 分析性能)
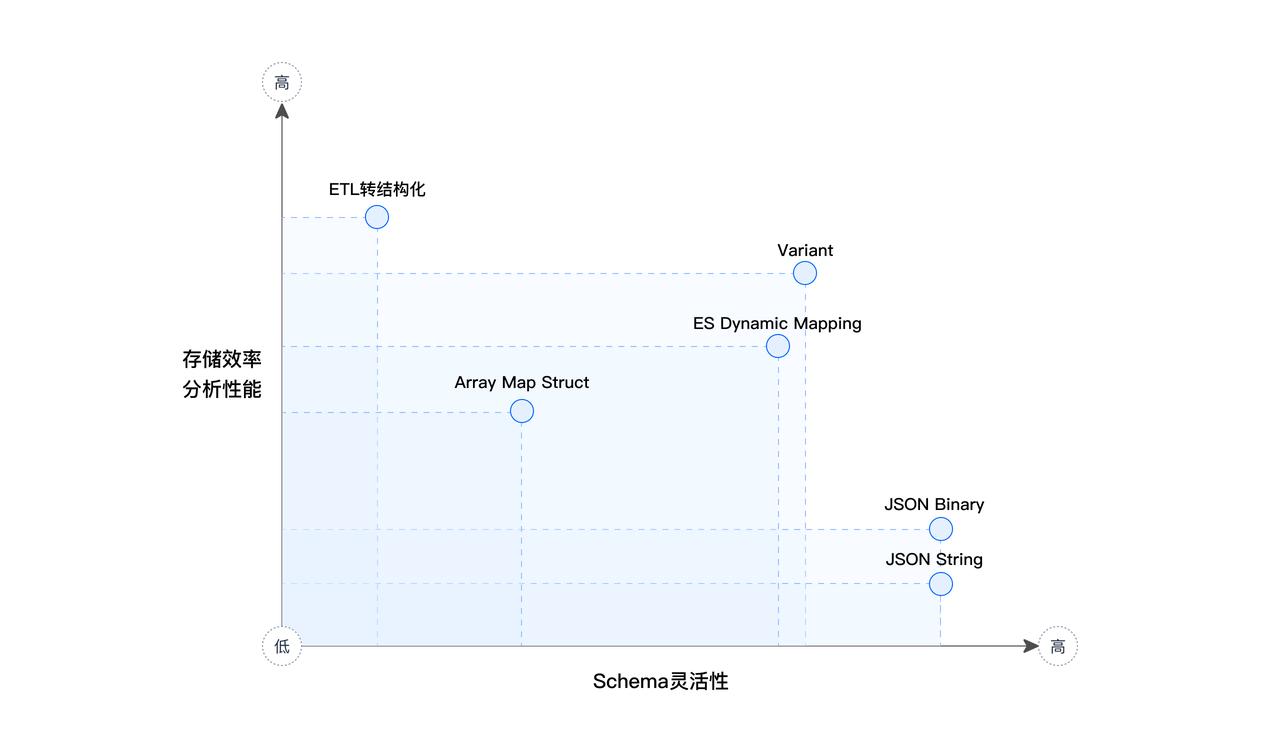
由上图可得出结论:
-
ETL 转结构化方案的的分析性能表现最佳,但 Schema 灵活性最差。
-
JSON String / Binary 的 Schema 灵活性最佳,但是其分析性能均比较低。
-
Doris VARIANT 和 Dynamic Mapping 在灵活性和性能方面表现均比较好,但整体而言 Doris VARIANT 更优,不仅是存储和分析性能强于 Dynamic Mapping,还体现在 VARIANT 能够很好解决字段类型固定和字段个数膨胀的痛点问题。
典型应用场景
接下来,我们将从用户常见的典型应用场景入手,介绍在不同场景中应选择哪种解决方案,以获得最佳的使用体验和性能表现。
01 用户画像与行为分析场景
在用户画像与行为场景中,有时会遇到包含多个值的复杂标签,比如 “喜欢的颜色”,可将颜色编号成整数,然后用 ARRAY<INT> 存储该标签。
CREATE TABLE `customer_profile` (
`rid` bigint NOT NULL,
`pid` bigint NOT NULL,
`last_update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`tag_cdp_1` int NULL,
`tag_cdp_2` varchar,
`tag_cdp_3` varchar,
`tag_cdp_4` int NULL,
`tag_cdp_5` varchar,
`tag_1` text NULL,
`tag_2` array<int> NULL,
`tag_3` int NULL,
`tag_4` text NULL,
`tag_5` array<int> NULL,
`tag_6` int NULL,
`tag_7` array<int> NULL
) ENGINE=OLAP
UNIQUE KEY(`rid`, `pid`)
DISTRIBUTED BY HASH(`rid`, `pid`) BUCKETS 30
查询时可以筛选多值标签是否包含某些值,比如使用 array_overlap 函数检查 tag_5 里面是否有 3, 6 或者 8。
SELECT * FROM customer_profile
WHERE pid = 1001
AND array_overlap(tag_5, [3, 6, 8])
02 数据湖查询加速场景
在数据湖查询加速场景中,在对接 Hive、Iceberg、Hudi 等外部数据源时,经常出现 ARRAY MAP STRUCT 等复杂嵌套数据类型,我们可以将这些数据类型直接映射到 Doris 内置的 ARRAY MAP STRUCT 类型。
如下示例,在 Doris 中创建 Hive CATALOG 并切换,可以快速读取 Hive 中的表。还可通过 DESC 查看表 st 结构中所包含的复杂嵌套类型,包括 ARRAY<FLOAT>类型 的 usage 字段、MAP<STRING, FLOAT>类型的 signal字段、MAP 嵌套 ARRAY 的 ext 扩展字段。
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.0.0.1:9083',
'hadoop.username' = 'hive'
);
SWITCH hive;
DESC st;
+--------+---------------------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------------------+------+-------+---------+-------+
| id | VARCHAR(255) | Yes | true | NULL | |
| status | TINYINT | Yes | false | NULL | |
| start | DATETIME | Yes | false | NULL | |
| end | DATETIME | Yes | false | NULL | |
| usage | ARRAY<FLOAT> | Yes | false | NULL | |
| signal | MAP<STRING, FLOAT> | Yes | false | NULL | |
| ext | MAP<STRING, ARRAY<INT>> | Yes | false | NULL | |
+--------+---------------------------+------+------+---------+-------+
下面的查询首先筛选出 2013-11-04 的数据,然后从ext这个 MAP 字段中,筛选出 Key 为'tags' 的 ARRAY 中包含55的记录,最后按status字段进行分组,使用array_avg函数计算usage这个 ARRAY 类型字段的平均值。
SELECT status, avg(array_avg(usage)) as avg_usage FROM st
WHERE array_contains(ext['tags'], 55)
AND start >= '2013-11-04 00:00:00'
AND end <= '2013-11-04 23:59:59'
GROUP BY status;
03 Log 场景
在日志存储和分析的场景中,日志数据通常包含一些静态字段(时间戳、机器名称、文件路径)、日志文本消息以及扩展字段。扩展字段用于存储不固定的信息或属性,例如某个日志中可能包含一个名为ext的扩展字段,用于记录与日志相关的特定信息或数据。如下所示:
{
"time": 2024-04-09 16:06:03.684886
"source": "fluentd_tcp"
"host": "host1"
"status": "info"
"filepath": "path1"
"container_id": "xxx"
"container_name": "xxx"
"message": "....."
"ext": {
"nameSpace": "kube-public",
"level": "info",
"service": "console-media",
"category": "debug",
"tag": "[]",
"serviceID": "console-media-6b57fc7758-nplck",
"date_ns": 886517,
"index": "default",
"cluster": "UcloudKubernetes"
}
}
包含扩展字段的日志数据结构使得数据扩展更加便捷、灵活和多样化,但也对数据的存储和分析技术提出了更高的要求。而使用 VARIANT 可以很好的解决这一问题。
在建表时,如果扩展字段ext使用 VARIANT 类型,可使数据灵活写入。
CREATE TABLE log (
`time` datetime(6) NULL,
`source` text NULL,
`host` text NULL,
`status` text NULL,
`filepath` text NULL,
`container_id` text NULL,
`container_name` text NULL,
`message` text NULL,
`ext` variant NULL,
INDEX idx1 (`message`) USING INVERTED PROPERTIES("parser" = "chinese")
)
在查询时,可以使用特定的语法访问 VARIANT 的子列。如下所示的查询中,主要按照时间和服务名称来统计错误数量。
-
首先,在
WHERE条件中将时间戳转换为小时单位,并提取出EXT字段中的service字段值。 -
接着,计算满足条件的记录数量(
count)并进行聚合。如需提取namespace字段时(variant类型的子字段),无需读取整个 VARIANT 字段的内容,而只需访问 VARIANT 扩展的特定子列即可,这种数据访问方式使得查询性能更高。 -
最后,按照小时和服务名称对结果进行分组,并按时间进行排序,就可以得到一个错误趋势图。该趋势图可帮助用户直观地了解系统在不同时间段内的错误发生情况,为故障排查和性能优化提供有力支持。
SELECT
hour_floor(`time`) as hour,
cast (ext['service'] as text) as service,
count() as cnt
FROM log WHERE time >= t1 AND time < t2
AND (`status` = "error") AND (`source` = "abc")
AND ext['nameSpace'] = "bcd"
GROUP BY hour, service
ORDER BY hour LIMIT 100;
在日志场景使用 VARIANT 的优势在于:
-
允许字段类型变化,不会因为数据变化而出现写入异常。
-
可自动处理扩展字段增减,过期删除的数据字段不会残留。
-
相比 String 或 JSON ,其压缩率更高、分析性能也更强。
04 Trace 场景
Trace 场景通常应用于可观测领域,特别是在容器化微服务环境中。在这种环境下,服务之间的调用可能会产生大量的跟踪数据。例如,一个请求可能经过多个服务,每个服务都会生成一条 Trace 数据,这些 Trace 数据对于问题诊断和性能分析至关重要。
Trace 通常包含attrs属性字段,这些字段均是可扩展的。由于不同的模块和服务输出的格式可能有所不同,因此无法要求其具备固定的 Schema。在其他数据库中,通常会使用 Map 来存储 attrs字段,Map 的 Key 的个数是可以扩展的,但在查询某个 Key 对应的 Value 时,需要遍历所有 Key Value 对,性能较低,而这个操作在 Trace 场景中比较常见。
{
"time: "2024-04-09 16:13:51.381141",
"message": "...",
"__namespace": "tracing",
"source": "opentelemetry",
"service": "iov-fleet-mqtt",
"operation": "fleet/ListFleets",
"status: "ok",
"parent_id": "0",
"resource": "fleet/ListFleets",
"span_id": "xxxx",
"trace_id": "xxxx",
"duration": 3810,
"start": 1712650431181241,
"attrs": {
"rpc_system": "grpc",
"rpc_method": "ListFleets",
"service_sub": "iov-fleet-mqtt",
"k8s_cluster": "sh-test-uk8s",
"date_ns": 141210,
"rpc_service": "fleet.FleetService",
"service_name": "iov-fleet-mqtt",
"rpc_grpc_status_code": 0
}
}
为了更好的满足这种需求,可以使用 Doris 的 VARIANT 列类型来存储 attrs 字段。当进行查询分析时,与 Log 场景类似,可以根据特定条件高效地筛选和提取这些属性字段,避免遍历整个 Map 的性能开销。
CREATE TABLE trace (
`time` datetime(6) NULL,
`message` text NULL,
`source` text NULL,
`service` text NULL,
`endpoint` text NULL,
`operation` text NULL,
`status` text NULL,
`parent_id` text NULL,
`resource` text NULL,
`span_id` text NULL,
`trace_id` text NULL,
`duration` bigint(20) NULL,
`start` bigint(20) NULL,
`attrs` variant NULL
)
例如,如果查询中涉及到'e``rror``_``stack``'`` ``IS NOT NULL的条件,使用 VARIANT 列的查询效率比较高,原因是无需读取整个attribute的 JSON 结构,只需读取与errorStack相关的部分。此外,通过利用索引(如 ZoneMap 索引或倒排索引),可以进一步加速此类查询。
SELECT
`time`, `message`, `source`, `service`, `endpoint`, `operation`, `status`, `parent_id`, `resource`, `span_id`, `trace_id`, `duration`, `start`, cast(`attrs` as text) as `attrs`
FROM trace
WHERE time >= t1 AND time < t2
AND `service` = "pms-java-gate"
AND attrs['error_stack'] IS NOT NULL
ORDER BY `time` DESC LIMIT 50
在 Trace 场景下,VARIANT 有下面一些优势:
- 按 Trace 扩展字段中的某一个进行筛选,效率比 JSON 和 MAP 更高。
- 相比 JSON 或 MAP,其存储压缩率更高。
- Trace 扩展字段可以随意增减。
05 IoT 车联网
IoT 车联网场景中,有许多设备或车辆具备标签字段(如 tags),这些字段可能包含数值和数组。
{
"date": 20240114,
"plate_name": "xxx",
"base_dir": "xxx",
"pack_dir": "xxx",
"naive_gt_dir": "xxx",
"gt_dir": "xxx",
"sync_dir": "xxx",
"sync_index": [1755],
"lidar_dir": "xxx",
"calib_dir": "xxx",
"weather": NULL,
"scene": NULL,
"tags": {
"a": 2,
"b": [0,1,0,0,1],
"c": [0,0,0,0,0],
"d": 0
}
}
建表时,tags 字段使用 VARIANT 类型。
CREATE TABLE cars (
`time` datetime(6),
`name` TEXT,
`base_dir` TEXT,
`pack_dir` TEXT,
`naive_gt_dir` TEXT,
`gt_dir` TEXT,
`sync_dir` TEXT,
`lidar_dir` TEXT,
`calib_dir` TEXT,
`weather` TEXT,
`scene` TEXT,
`tags` VARIANT
)
查询时,对于 tags 里面的数值字段 a 可以用普通的比较条件,对于 tags 中的数组字段 b,可以使用 array_contains 来检查是否包含特定值。
SELECT *
FROM cars
WHERE
time >= t1 AND time < t2
AND tags['a'] > 10
AND array_contains(tags['b'], 1)
ORDER BY time DESC LIMIT 100
在 IoT 和车联网场景下,VARIANT 的优势主要包含以下几点:
-
相对于时序数据库或物联网数据库 OLAP 分析功能更丰富,列式存储分析性能更好。
-
支持上千稀疏列,在实际应用中,许多设备的标签字段不一样,可能只有部分设备包含特定标签。VARIANT 利用稀疏列的特性,避免了将稀疏字段拆分为多个独立列,从而提高了存储效率。此外,由于数据在一段时间内往往具有局部性,即某段时间内上报的数据在标签上可能较为密集,但整体来看则相对稀疏。
-
有更高的压缩率,特别是相较于 String 和 JSON 类型。
结束语
以上就是 Apache Doris 关于半结构化数据 JSON 的解决方案,不论是 Array Map Struct 、JSON 还是 VARIANT 方案,均没有绝对的优劣之分,可通过实际的应用场景,选择最合适的解决方案。






















































